第四天 Kubernetes集群的日志及监控
k8s日志收集架构
https://kubernetes.io/docs/concepts/cluster-administration/logging/
总体分为三种方式:
- 使用在每个节点上运行的节点级日志记录代理。
- 在应用程序的 pod 中,包含专门记录日志的 sidecar 容器。
- 将日志直接从应用程序中推送到日志记录后端。
使用节点级日志代理
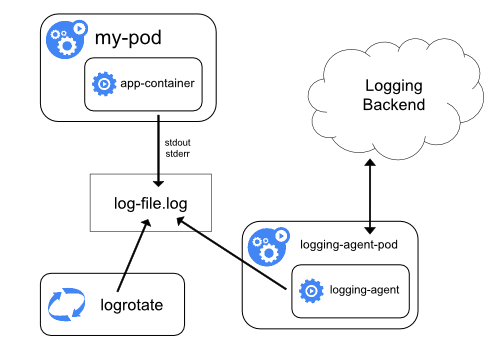
容器日志驱动:
https://docs.docker.com/config/containers/logging/configure/
查看当前的docker主机的驱动:
$ docker info --format '{{.LoggingDriver}}'
json-file格式,docker会默认将标准和错误输出保存为宿主机的文件,路径为:
/var/lib/docker/containers/<container-id>/<container-id>-json.log
并且可以设置日志轮转:
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3",
"labels": "production_status",
"env": "os,customer"
}
}
优势:
- 部署方便,使用DaemonSet类型控制器来部署agent即可
- 对业务应用的影响最小,没有侵入性
劣势:
- 只能收集标准和错误输出,对于容器内的文件日志,暂时收集不到
使用 sidecar 容器和日志代理
-
方式一:sidecar 容器将应用程序日志传送到自己的标准输出。
思路:在pod中启动一个sidecar容器,把容器内的日志文件吐到标准输出,由宿主机中的日志收集agent进行采集。
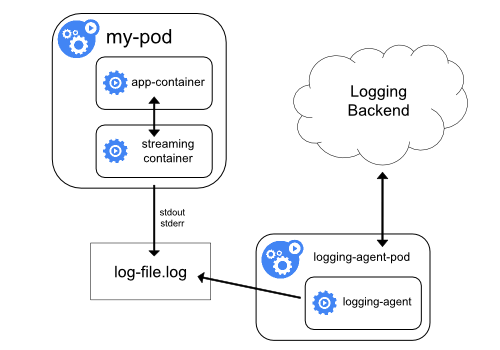
$ cat count-pod.yaml apiVersion: v1 kind: Pod metadata: name: counter spec: containers: - name: count image: busybox args: - /bin/sh - -c - > i=0; while true; do echo "$i: $(date)" >> /var/log/1.log; echo "$(date) INFO $i" >> /var/log/2.log; i=$((i+1)); sleep 1; done volumeMounts: - name: varlog mountPath: /var/log - name: count-log-1 image: busybox args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log'] volumeMounts: - name: varlog mountPath: /var/log - name: count-log-2 image: busybox args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log'] volumeMounts: - name: varlog mountPath: /var/log volumes: - name: varlog emptyDir: {} $ kubectl create -f counter-pod.yaml $ kubectl logs -f counter -c count-log-1优势:
- 可以实现容器内部日志收集
- 对业务应用的侵入性不大
劣势:
- 每个业务pod都需要做一次改造
- 增加了一次日志的写入,对磁盘使用率有一定影响
-
方式二:sidecar 容器运行一个日志代理,配置该日志代理以便从应用容器收集日志。
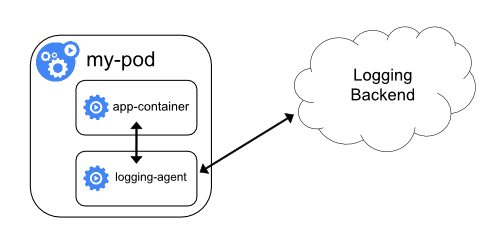
思路:直接在业务Pod中使用sidecar的方式启动一个日志收集的组件(比如fluentd),这样日志收集可以将容器内的日志当成本地文件来进行收取。
优势:不用往宿主机存储日志,本地日志完全可以收集
劣势:每个业务应用额外启动一个日志agent,带来额外的资源损耗
从应用中直接暴露日志目录
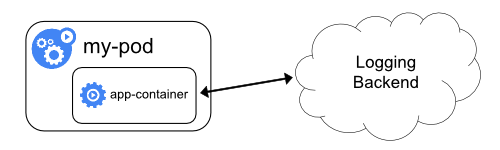
企业日志方案选型
目前来讲,最建议的是采用节点级的日志代理。
方案一:自研方案,实现一个自研的日志收集agent,大致思路:
- 针对容器的标准输出及错误输出,使用常规的方式,监听宿主机中的容器输出路径即可
- 针对容器内部的日志文件
- 在容器内配置统一的环境变量,比如LOG_COLLECT_FILES,指定好容器内待收集的日志目录及文件
- agent启动的时候挂载docker.sock文件及磁盘的根路径
- 监听docker的容器新建、删除事件,通过docker的api,查出容器的存储、环境变量、k8s属性等信息
- 配置了LOG_COLLECT_FILES环境变量的容器,根据env中的日志路径找到主机中对应的文件路径,然后生成收集的配置文件
- agent与开源日志收集工具(Fluentd或者filebeat等)配合,agent负责下发配置到收集工具中并对进程做reload
方案二:日志使用开源的Agent进行收集(EFK方案),适用范围广,可以满足绝大多数日志收集、展示的需求。
实践使用EFK实现业务日志收集
EFK架构工作流程
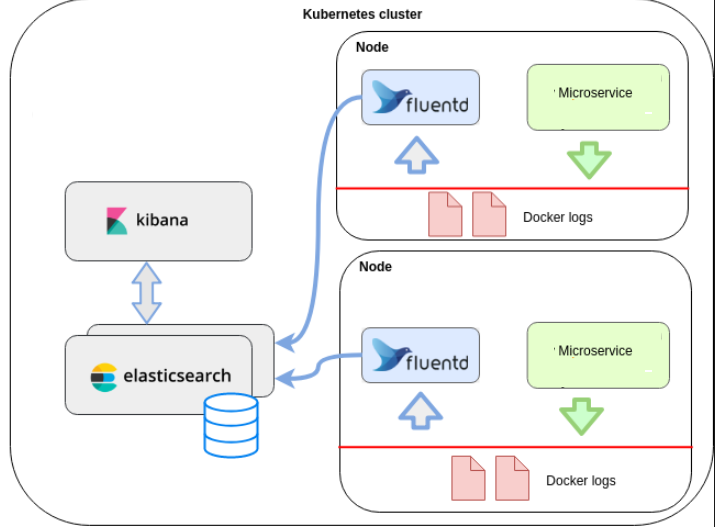
-
Elasticsearch
一个开源的分布式、Restful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
-
Kibana
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。可以通过Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。也可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。
-
一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
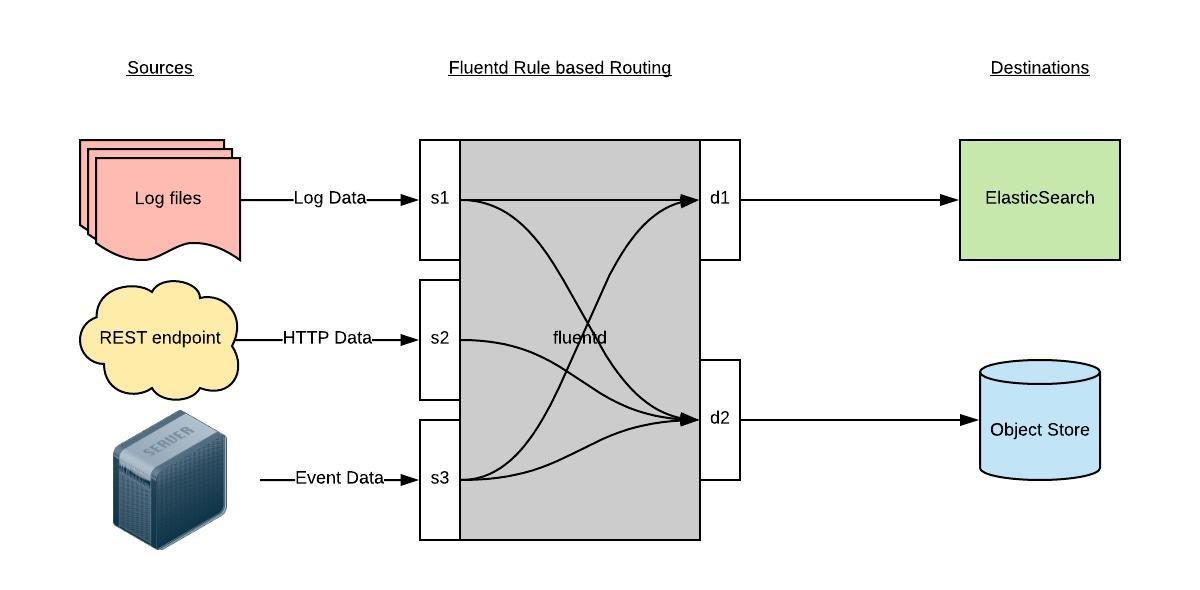
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储、kafka等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务
Fluentd精讲
Fluentd架构
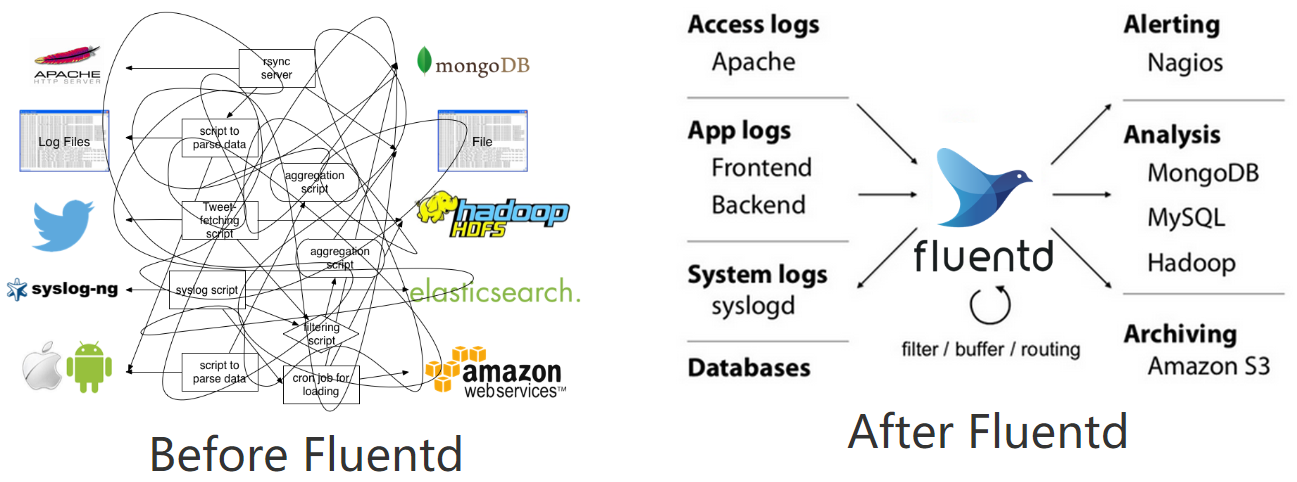
为什么推荐使用fluentd作为k8s体系的日志收集工具?
-
云原生:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch
-
将日志文件JSON化

-
可插拔架构设计
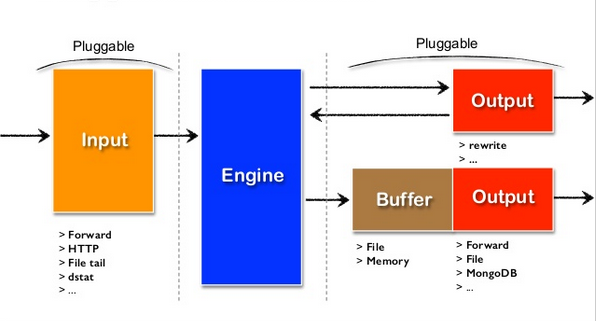
-
极小的资源占用
基于C和Ruby语言, 30-40MB,13,000 events/second/core

-
极强的可靠性
- 基于内存和本地文件的缓存
- 强大的故障转移
fluentd事件流的生命周期及指令配置
https://docs.fluentd.org/v/0.12/quickstart/life-of-a-fluentd-event
Input -> filter 1 -> ... -> filter N -> Buffer -> Output
启动命令
$ fluentd -c fluent.conf
指令介绍:
-
source ,数据源,对应Input 通过使用 source 指令,来选择和配置所需的输入插件来启用 Fluentd 输入源, source 把事件提交到 fluentd 的路由引擎中。使用type来区分不同类型的数据源。如下配置可以监听指定文件的追加输入:
<source> @type tail path /var/log/httpd-access.log pos_file /var/log/td-agent/httpd-access.log.pos tag myapp.access format apache2 </source> -
filter,Event processing pipeline(事件处理流)
filter 可以串联成 pipeline,对数据进行串行处理,最终再交给 match 输出。 如下可以对事件内容进行处理:
<source> @type http port 9880 </source> <filter myapp.access> @type record_transformer <record> host_param “#{Socket.gethostname}” </record> </filter>filter 获取数据后,调用内置的 @type record_transformer 插件,在事件的 record 里插入了新的字段 host_param,然后再交给 match 输出。
-
label指令
可以在
source里指定@label,这个 source 所触发的事件就会被发送给指定的 label 所包含的任务,而不会被后续的其他任务获取到。<source> @type forward </source> <source> ### 这个任务指定了 label 为 @SYSTEM ### 会被发送给 <label @SYSTEM> ### 而不会被发送给下面紧跟的 filter 和 match @type tail @label @SYSTEM path /var/log/httpd-access.log pos_file /var/log/td-agent/httpd-access.log.pos tag myapp.access format apache2 </source> <filter access.**> @type record_transformer <record> # … </record> </filter> <match **> @type elasticsearch # … </match> <label @SYSTEM> ### 将会接收到上面 @type tail 的 source event <filter var.log.middleware.**> @type grep # … </filter> <match **> @type s3 # … </match> </label> -
match,匹配输出
查找匹配 “tags” 的事件,并处理它们。match 命令的最常见用法是将事件输出到其他系统(因此,与 match 命令对应的插件称为 “输出插件”)
<source> @type http port 9880 </source> <filter myapp.access> @type record_transformer <record> host_param “#{Socket.gethostname}” </record> </filter> <match myapp.access> @type file path /var/log/fluent/access </match>
事件的结构:
time:事件的处理时间
tag:事件的来源,在fluentd.conf中配置
record:真实的日志内容,json对象
比如,下面这条原始日志:
192.168.0.1 - - [28/Feb/2013:12:00:00 +0900] "GET / HTTP/1.1" 200 777
经过fluentd 引擎处理完后的样子可能是:
2020-07-16 08:40:35 +0000 apache.access: {"user":"-","method":"GET","code":200,"size":777,"host":"192.168.0.1","path":"/"}
fluentd的buffer事件缓冲模型
Input -> filter 1 -> ... -> filter N -> Buffer -> Output
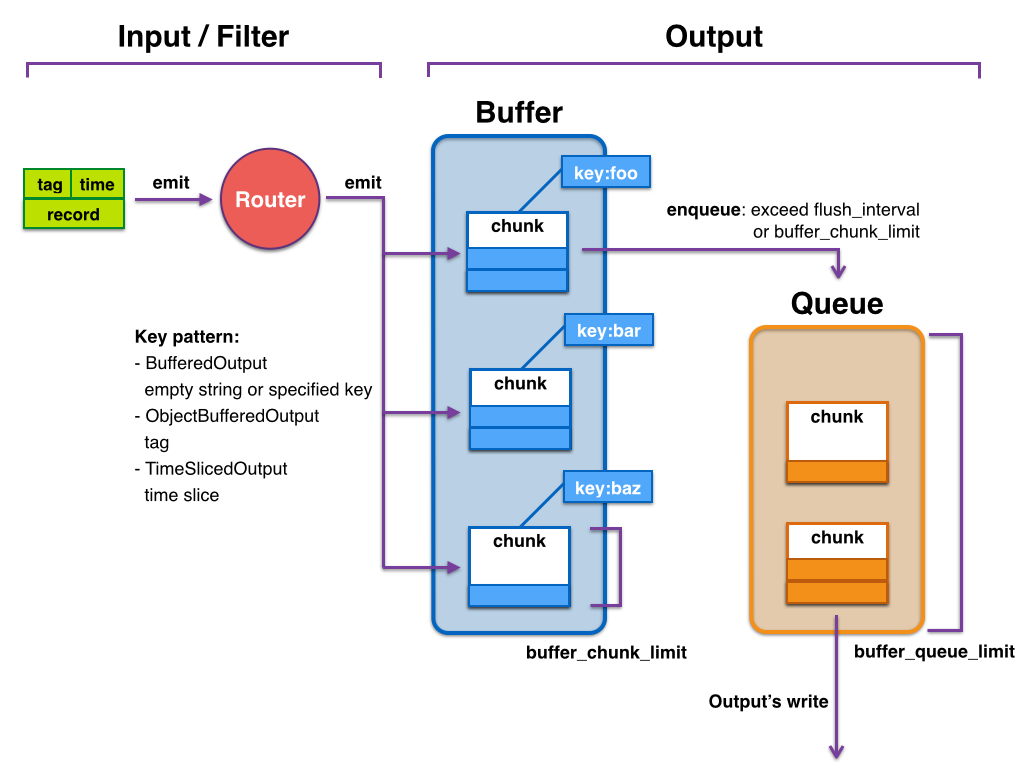
因为每个事件数据量通常很小,考虑数据传输效率、稳定性等方面的原因,所以基本不会每条事件处理完后都会立马写入到output端,因此fluentd建立了缓冲模型,模型中主要有两个概念:
- buffer_chunk:事件缓冲块,用来存储本地已经处理完待发送至目的端的事件,可以设置每个块的大小。
- buffer_queue:存储chunk的队列,可以设置长度
可以设置的参数,主要有:
- buffer_type,缓冲类型,可以设置file或者memory
- buffer_chunk_limit,每个chunk块的大小,默认8MB
- buffer_queue_limit ,chunk块队列的最大长度,默认256
- flush_interval ,flush一个chunk的时间间隔
- retry_limit ,chunk块发送失败重试次数,默认17次,之后就丢弃该chunk数据
- retry_wait ,重试发送chunk数据的时间间隔,默认1s,第2次失败再发送的话,间隔2s,下次4秒,以此类推
大致的过程为:
随着fluentd事件的不断生成并写入chunk,缓存块持变大,当缓存块满足buffer_chunk_limit大小或者新的缓存块诞生超过flush_interval时间间隔后,会推入缓存queue队列尾部,该队列大小由buffer_queue_limit决定。
每次有新的chunk入列,位于队列最前部的chunk块会立即写入配置的存储后端,比如配置的是kafka,则立即把数据推入kafka中。
比较理想的情况是每次有新的缓存块进入缓存队列,则立马会被写入到后端,同时,新缓存块也持续入列,但是入列的速度不会快于出列的速度,这样基本上缓存队列处于空的状态,队列中最多只有一个缓存块。
但是实际情况考虑网络等因素,往往缓存块被写入后端存储的时候会出现延迟或者写入失败的情况,当缓存块写入后端失败时,该缓存块还会留在队列中,等retry_wait时间后重试发送,当retry的次数达到retry_limit后,该缓存块被销毁(数据被丢弃)。
此时缓存队列持续有新的缓存块进来,如果队列中存在很多未及时写入到后端存储的缓存块的话,当队列长度达到buffer_queue_limit大小,则新的事件被拒绝,fluentd报错,error_class=Fluent::Plugin::Buffer::BufferOverflowError error=“buffer space has too many data”。
还有一种情况是网络传输缓慢的情况,若每3秒钟会产生一个新块,但是写入到后端时间却达到了30s钟,队列长度为100,那么每个块出列的时间内,又有新的10个块进来,那么队列很快就会被占满,导致异常出现。
实践一:实现业务应用日志的收集及字段解析
目标:收集容器内的nginx应用的access.log日志,并解析日志字段为JSON格式,原始日志的格式为:
$ tail -f access.log
...
53.49.146.149 1561620585.973 0.005 502 [27/Jun/2019:15:29:45 +0800] 178.73.215.171 33337 GET https
收集并处理成:
{
"serverIp": "53.49.146.149",
"timestamp": "1561620585.973",
"respondTime": "0.005",
"httpCode": "502",
"eventTime": "27/Jun/2019:15:29:45 +0800",
"clientIp": "178.73.215.171",
"clientPort": "33337",
"method": "GET",
"protocol": "https"
}
思路:
- 配置fluent.conf
- 使用@tail插件通过监听access.log文件
- 用filter实现对nginx日志格式解析
- 启动fluentd服务
- 手动追加内容至access.log文件
- 观察本地输出内容是否符合预期
fluent.conf
<source>
@type tail
@label @nginx_access
path /fluentd/access.log
pos_file /fluentd/nginx_access.posg
tag nginx_access
format none
@log_level trace
</source>
<label @nginx_access>
<filter nginx_access>
@type parser
key_name message
format /(?<serverIp>[^ ]*) (?<timestamp>[^ ]*) (?<respondTime>[^ ]*) (?<httpCode>[^ ]*) \[(?<eventTime>[^\]]*)\] (?<clientIp>[^ ]*) (?<clientPort>[^ ]*) (?<method>[^ ]*) (?<protocol>[^ ]*)/
</filter>
<match nginx_access>
@type stdout
</match>
</label>
启动服务,追加文件内容:
$ docker run -u root --rm -ti 172.21.51.67:5000/fluentd_elasticsearch/fluentd:v2.5.2 sh
/ # cd /fluentd/
/ # touch access.log
/ # fluentd -c /fluentd/etc/fluent.conf
/ # echo '53.49.146.149 1561620585.973 0.005 502 [27/Jun/2019:15:29:45 +0800] 178.73.215.171 33337 GET https' >>/fluentd/access.log
使用该网站进行正则校验: http://fluentular.herokuapp.com
实践二:使用ruby实现日志字段的转换及自定义处理
<source>
@type tail
@label @nginx_access
path /fluentd/access.log
pos_file /fluentd/nginx_access.posg
tag nginx_access
format none
@log_level trace
</source>
<label @nginx_access>
<filter nginx_access>
@type parser
key_name message
format /(?<serverIp>[^ ]*) (?<timestamp>[^ ]*) (?<respondTime>[^ ]*) (?<httpCode>[^ ]*) \[(?<eventTime>[^\]]*)\] (?<clientIp>[^ ]*) (?<clientPort>[^ ]*) (?<method>[^ ]*) (?<protocol>[^ ]*)/
</filter>
<filter nginx_access>
@type record_transformer
enable_ruby
<record>
host_name "#{Socket.gethostname}"
my_key "my_val"
tls ${record["protocol"].index("https") ? "true" : "false"}
</record>
</filter>
<match nginx_access>
@type stdout
</match>
</label>
ConfigMap的配置文件挂载使用场景
开始之前,我们先来回顾一下,configmap的常用的挂载场景。
场景一:单文件挂载到空目录
假如业务应用有一个配置文件,名为 application-1.conf,如果想将此配置挂载到pod的/etc/application/目录中。
application-1.conf的内容为:
$ cat application-1.conf
name: "application"
platform: "linux"
purpose: "demo"
company: "luffy"
version: "v2.1.0"
该配置文件在k8s中可以通过configmap来管理,通常我们有如下两种方式来管理配置文件:
-
通过kubectl命令行来生成configmap
# 通过文件直接创建 $ kubectl -n default create configmap application-config --from-file=application-1.conf # 会生成配置文件,查看内容,configmap的key为文件名字 $ kubectl -n default get cm application-config -oyaml -
通过yaml文件直接创建
$ cat application-config.yaml apiVersion: v1 kind: ConfigMap metadata: name: application-config namespace: default data: application-1.conf: | name: "application" platform: "linux" purpose: "demo" company: "luffy" version: "v2.1.0" # 创建configmap $ kubectl create -f application-config.yaml
准备一个demo-deployment.yaml文件,挂载上述configmap到/etc/application/中
$ cat demo-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo
namespace: default
spec:
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
volumes:
- configMap:
name: application-config
name: config
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: "/etc/application"
name: config
创建并查看:
$ kubectl create -f demo-deployment.yaml
修改configmap文件的内容,观察pod中是否自动感知变化:
$ kubectl edit cm application-config
整个configmap文件直接挂载到pod中,若configmap变化,pod会自动感知并拉取到pod内部。
但是pod内的进程不会自动重启,所以很多服务会实现一个内部的reload接口,用来加载最新的配置文件到进程中。
场景二:多文件挂载
假如有多个配置文件,都需要挂载到pod内部,且都在一个目录中
$ cat application-1.conf
name: "application-1"
platform: "linux"
purpose: "demo"
company: "luffy"
version: "v2.1.0"
$ cat application-2.conf
name: "application-2"
platform: "linux"
purpose: "demo"
company: "luffy"
version: "v2.1.0"
同样可以使用两种方式创建:
$ kubectl delete cm application-config
$ kubectl create cm application-config --from-file=application-1.conf --from-file=application-2.conf
$ kubectl get cm application-config -oyaml
观察Pod已经自动获取到最新的变化
$ kubectl exec demo-55c649865b-gpkgk ls /etc/application/
application-1.conf
application-2.conf
此时,是挂载到pod内的空目录中/etc/application,假如想挂载到pod已存在的目录中,比如:
$ kubectl exec demo-55c649865b-gpkgk ls /etc/profile.d
color_prompt
locale
更改deployment的挂载目录:
$ cat demo-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo
namespace: default
spec:
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
volumes:
- configMap:
name: application-config
name: config
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: "/etc/profile.d"
name: config
重建pod
$ kubectl apply -f demo-deployment.yaml
# 查看pod内的/etc/profile.d目录,发现已有文件被覆盖
$ kubectl exec demo-77d685b9f7-68qz7 ls /etc/profile.d
application-1.conf
application-2.conf
场景三 挂载子路径
实现多个配置文件,可以挂载到pod内的不同的目录中。比如:
application-1.conf挂载到/etc/application/application-2.conf挂载到/etc/profile.d
configmap保持不变,修改deployment文件:
$ cat demo-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo
namespace: default
spec:
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
volumes:
- name: config
configMap:
name: application-config
items:
- key: application-1.conf
path: application1
- key: application-2.conf
path: application2
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: "/etc/application/application-1.conf"
name: config
subPath: application1
- mountPath: "/etc/profile.d/application-2.conf"
name: config
subPath: application2
测试挂载:
$ kubectl apply -f demo-deployment.yaml
$ kubectl exec demo-78489c754-shjhz ls /etc/application
application-1.conf
$ kubectl exec demo-78489c754-shjhz ls /etc/profile.d/
application-2.conf
color_prompt
locale
使用subPath挂载到Pod内部的文件,不会自动感知原有ConfigMap的变更
部署es服务
部署分析
- es生产环境是部署es集群,通常会使用statefulset进行部署
- es默认使用elasticsearch用户启动进程,es的数据目录是通过宿主机的路径挂载,因此目录权限被主机的目录权限覆盖,因此可以利用initContainer容器在es进程启动之前把目录的权限修改掉,注意init container要用特权模式启动。
- 若希望使用helm部署,参考 https://github.com/helm/charts/tree/master/stable/elasticsearch
使用StatefulSet管理有状态服务
使用Deployment创建多副本的pod的情况:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
labels:
app: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx-deployment
template:
metadata:
labels:
app: nginx-deployment
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
使用StatefulSet创建多副本pod的情况:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: default
labels:
app: nginx-sts
spec:
replicas: 3
serviceName: "nginx"
selector:
matchLabels:
app: nginx-sts
template:
metadata:
labels:
app: nginx-sts
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
无头服务Headless Service
kind: Service
apiVersion: v1
metadata:
name: nginx
namespace: default
spec:
selector:
app: nginx-sts
ports:
- protocol: TCP
port: 80
targetPort: 80
clusterIP: None
$ kubectl -n default exec -ti nginx-statefulset-0 sh
/ # curl nginx-statefulset-2.nginx
部署并验证
es-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: es-config
namespace: logging
data:
elasticsearch.yml: |
cluster.name: "luffy-elasticsearch"
node.name: "${POD_NAME}"
network.host: 0.0.0.0
discovery.seed_hosts: "es-svc-headless"
cluster.initial_master_nodes: "elasticsearch-0,elasticsearch-1,elasticsearch-2"
es-svc-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: es-svc-headless
namespace: logging
labels:
k8s-app: elasticsearch
spec:
selector:
k8s-app: elasticsearch
clusterIP: None
ports:
- name: in
port: 9300
protocol: TCP
es-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: logging
labels:
k8s-app: elasticsearch
spec:
replicas: 3
serviceName: es-svc-headless
selector:
matchLabels:
k8s-app: elasticsearch
template:
metadata:
labels:
k8s-app: elasticsearch
spec:
initContainers:
- command:
- /sbin/sysctl
- -w
- vm.max_map_count=262144
image: alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
- name: fix-permissions
image: alpine:3.6
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: es-data-volume
mountPath: /usr/share/elasticsearch/data
containers:
- name: elasticsearch
image: 172.21.51.67:5000/elasticsearch/elasticsearch:7.4.2
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
resources:
limits:
cpu: '1'
memory: 2Gi
requests:
cpu: '1'
memory: 2Gi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: es-config-volume
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
subPath: elasticsearch.yml
- name: es-data-volume
mountPath: /usr/share/elasticsearch/data
volumes:
- name: es-config-volume
configMap:
name: es-config
items:
- key: elasticsearch.yml
path: elasticsearch.yml
volumeClaimTemplates:
- metadata:
name: es-data-volume
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 5Gi
es-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: es-svc
namespace: logging
labels:
k8s-app: elasticsearch
spec:
selector:
k8s-app: elasticsearch
ports:
- name: out
port: 9200
protocol: TCP
$ kubectl create namespace logging
## 部署服务
$ kubectl create -f es-config.yaml
$ kubectl create -f es-svc-headless.yaml
$ kubectl create -f es-sts.yaml
$ kubectl create -f es-svc.yaml
## 等待片刻,查看一下es的pod部署到了k8s-slave1节点,状态变为running
$ kubectl -n logging get po -o wide
NAME READY STATUS RESTARTS AGE IP
elasticsearch-0 1/1 Running 0 15m 10.244.0.126
elasticsearch-1 1/1 Running 0 15m 10.244.0.127
elasticsearch-2 1/1 Running 0 15m 10.244.0.128
# 然后通过curl命令访问一下服务,验证es是否部署成功
$ kubectl -n logging get svc
es-svc ClusterIP 10.104.226.175 <none> 9200/TCP 2s
es-svc-headless ClusterIP None <none> 9300/TCP 32m
$ curl 10.104.226.175:9200
{
"name" : "elasticsearch-2",
"cluster_name" : "luffy-elasticsearch",
"cluster_uuid" : "7FDIACx9T-2ajYcB5qp4hQ",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
部署kibana
部署分析
-
kibana需要暴露web页面给前端使用,因此使用ingress配置域名来实现对kibana的访问
-
kibana为无状态应用,直接使用Deployment来启动
-
kibana需要访问es,直接利用k8s服务发现访问此地址即可,http://es-svc:9200
部署并验证
efk/kibana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: "kibana"
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: 172.21.51.67:5000/kibana/kibana:7.4.2
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_HOSTS
value: http://es-svc:9200
- name: SERVER_NAME
value: kibana-logging
- name: SERVER_REWRITEBASEPATH
value: "false"
ports:
- containerPort: 5601
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
protocol: TCP
targetPort: 5601
type: ClusterIP
selector:
app: kibana
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: logging
spec:
rules:
- host: kibana.luffy.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601
$ kubectl create -f kibana.yaml
deployment.apps/kibana created
service/kibana created
ingress/kibana created
## 配置域名解析 kibana.luffy.com,并访问服务进行验证,若可以访问,说明连接es成功
Fluentd服务部署
部署分析
- fluentd为日志采集服务,kubernetes集群的每个业务节点都有日志产生,因此需要使用daemonset的模式进行部署
- 为进一步控制资源,会为daemonset指定一个选择标签,fluentd=true来做进一步过滤,只有带有此标签的节点才会部署fluentd
- 日志采集,需要采集哪些目录下的日志,采集后发送到es端,因此需要配置的内容比较多,我们选择使用configmap的方式把配置文件整个挂载出来
部署服务
efk/fluentd-es-config-main.yaml
apiVersion: v1
data:
fluent.conf: |-
# This is the root config file, which only includes components of the actual configuration
#
# Do not collect fluentd's own logs to avoid infinite loops.
<match fluent.**>
@type null
</match>
@include /fluentd/etc/config.d/*.conf
kind: ConfigMap
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
name: fluentd-es-config-main
namespace: logging
配置文件,fluentd-config.yaml,注意点:
- 数据源source的配置,k8s会默认把容器的标准和错误输出日志重定向到宿主机中
- 默认集成了 kubernetes_metadata_filter 插件,来解析日志格式,得到k8s相关的元数据,raw.kubernetes
- match输出到es端的flush配置
efk/fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head false
</source>
# Detect exceptions in the log output and forward them as one log entry.
# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
hosts elasticsearch-0.es-svc-headless:9200,elasticsearch-1.es-svc-headless:9200,elasticsearch-2.es-svc-headless:9200
#port 9200
logstash_format true
#index_name kubernetes-%Y.%m.%d
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
daemonset定义文件,fluentd.yaml,注意点:
- 需要配置rbac规则,因为需要访问k8s api去根据日志查询元数据
- 需要将/var/log/containers/目录挂载到容器中
- 需要将fluentd的configmap中的配置文件挂载到容器内
- 想要部署fluentd的节点,需要添加fluentd=true的标签
efk/fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: fluentd-es
name: fluentd-es
namespace: logging
spec:
selector:
matchLabels:
k8s-app: fluentd-es
template:
metadata:
labels:
k8s-app: fluentd-es
spec:
containers:
- env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
image: 172.21.51.67:5000/fluentd_elasticsearch/fluentd:v2.5.2
imagePullPolicy: IfNotPresent
name: fluentd-es
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- mountPath: /var/log
name: varlog
- mountPath: /var/lib/docker/containers
name: varlibdockercontainers
readOnly: true
- mountPath: /fluentd/etc/config.d
name: config-volume
- mountPath: /fluentd/etc/fluent.conf
name: config-volume-main
subPath: fluent.conf
nodeSelector:
fluentd: "true"
securityContext: {}
serviceAccount: fluentd-es
serviceAccountName: fluentd-es
volumes:
- hostPath:
path: /var/log
type: ""
name: varlog
- hostPath:
path: /var/lib/docker/containers
type: ""
name: varlibdockercontainers
- configMap:
defaultMode: 420
name: fluentd-config
name: config-volume
- configMap:
defaultMode: 420
items:
- key: fluent.conf
path: fluent.conf
name: fluentd-es-config-main
name: config-volume-main
## 给slave1打上标签,进行部署fluentd日志采集服务
$ kubectl label node k8s-slave1 fluentd=true
$ kubectl label node k8s-slave2 fluentd=true
# 创建服务
$ kubectl create -f fluentd-es-config-main.yaml
configmap/fluentd-es-config-main created
$ kubectl create -f fluentd-configmap.yaml
configmap/fluentd-config created
$ kubectl create -f fluentd.yaml
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
daemonset.extensions/fluentd-es created
## 然后查看一下pod是否已经在k8s-slave1
$ kubectl -n logging get po -o wide
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 123m
fluentd-es-246pl 1/1 Running 0 2m2s
kibana-944c57766-ftlcw 1/1 Running 0 50m
上述是简化版的k8s日志部署收集的配置,完全版的可以提供 https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch 来查看。
EFK功能验证
验证思路
在slave节点中启动服务,同时往标准输出中打印测试日志,到kibana中查看是否可以收集
创建测试容器
efk/test-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
nodeSelector:
fluentd: "true"
containers:
- name: count
image: alpine:3.6
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
$ kubectl get po
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 6s
配置kibana
登录kibana界面,按照截图的顺序操作:
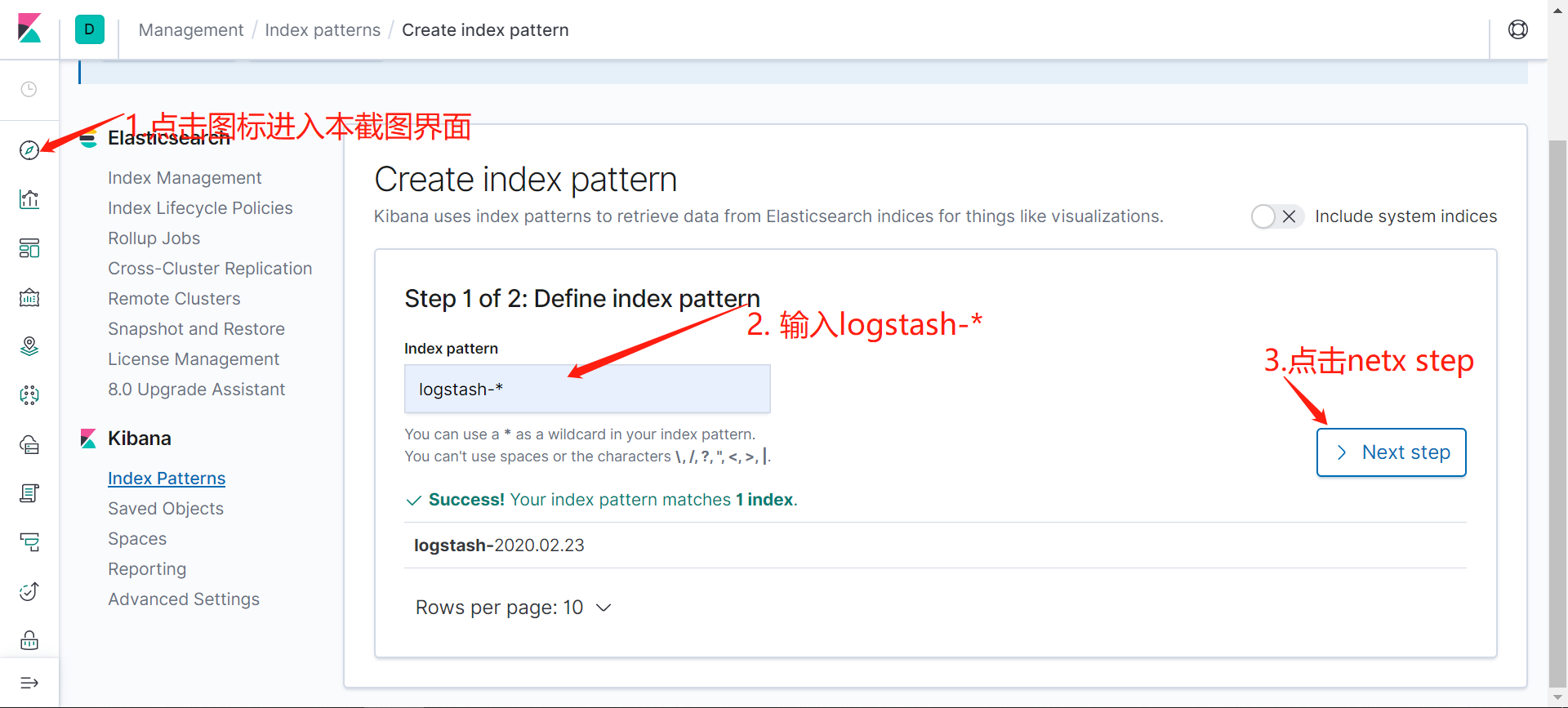
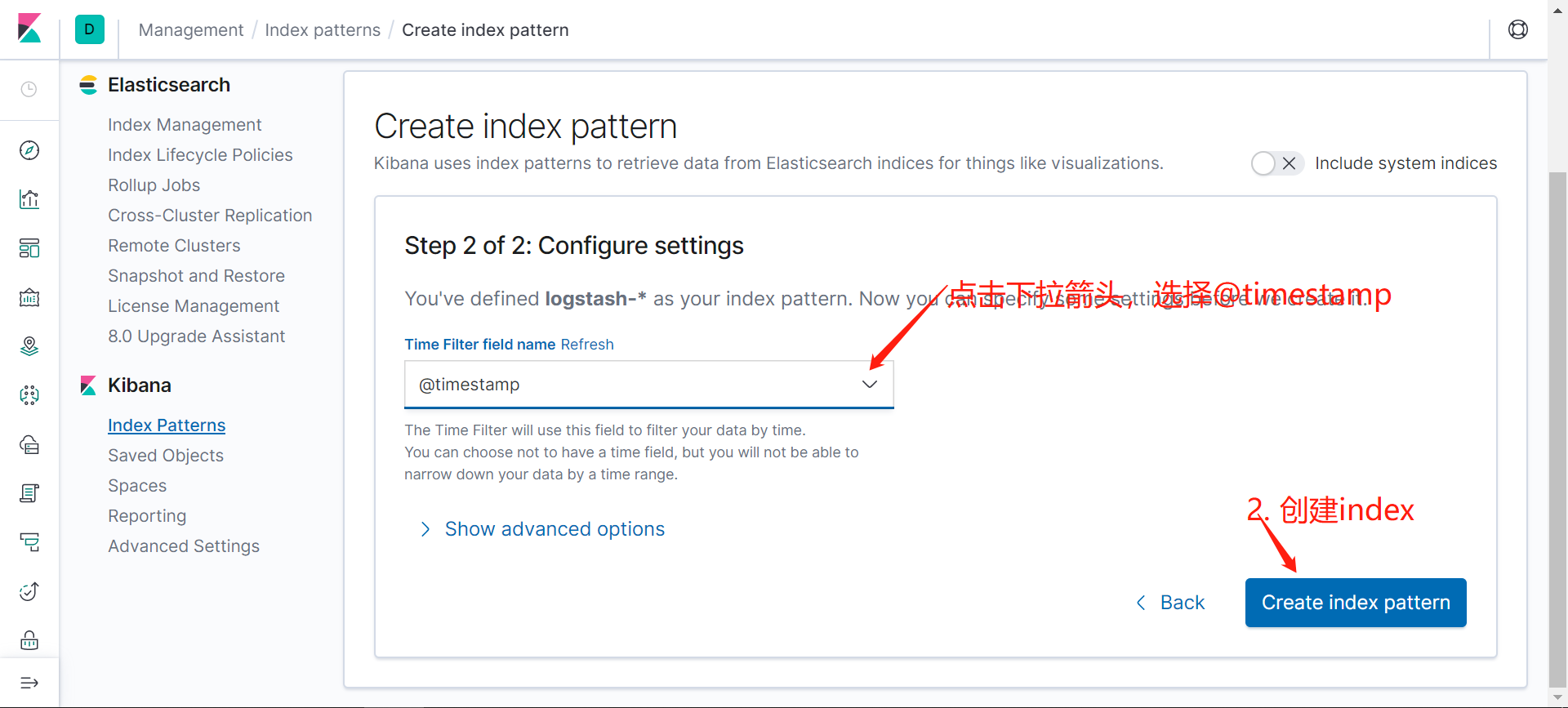
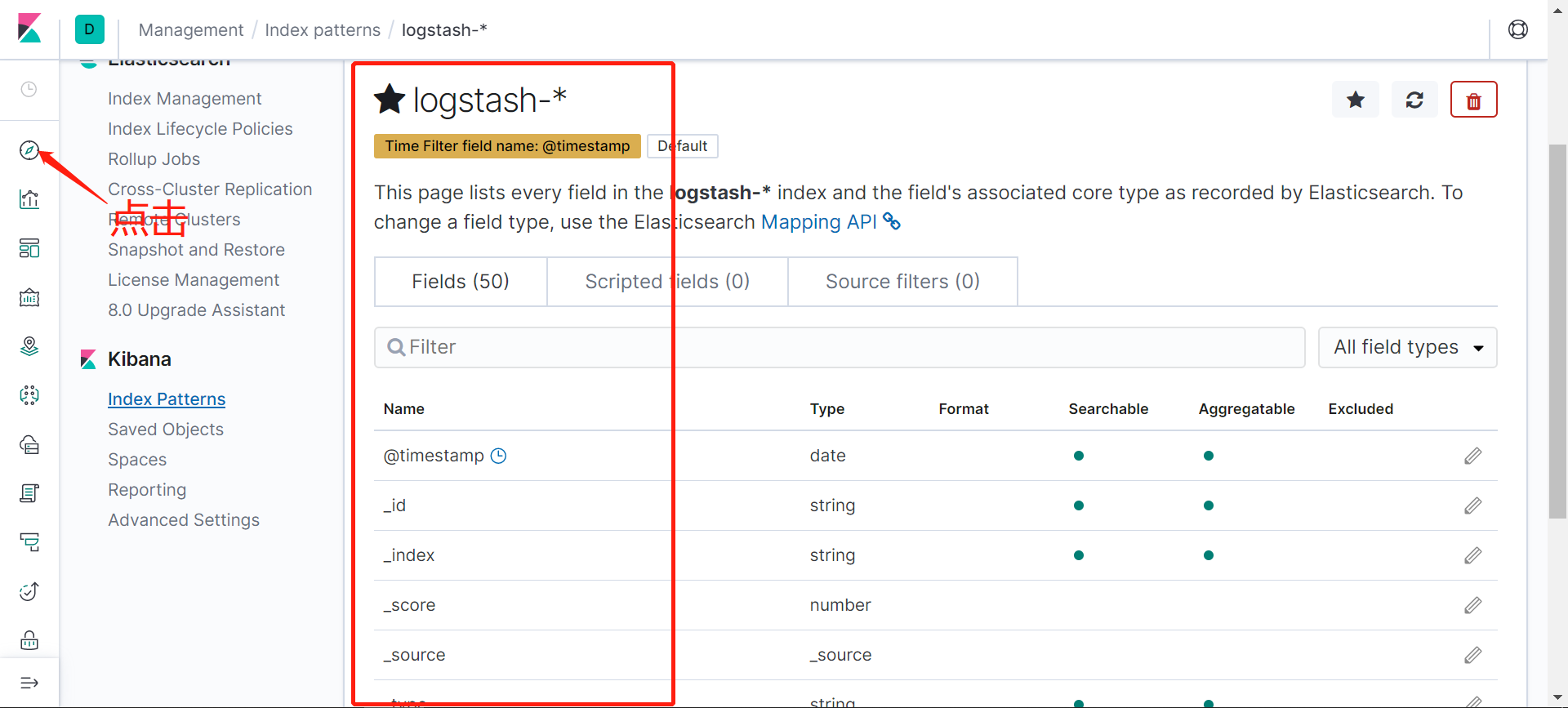
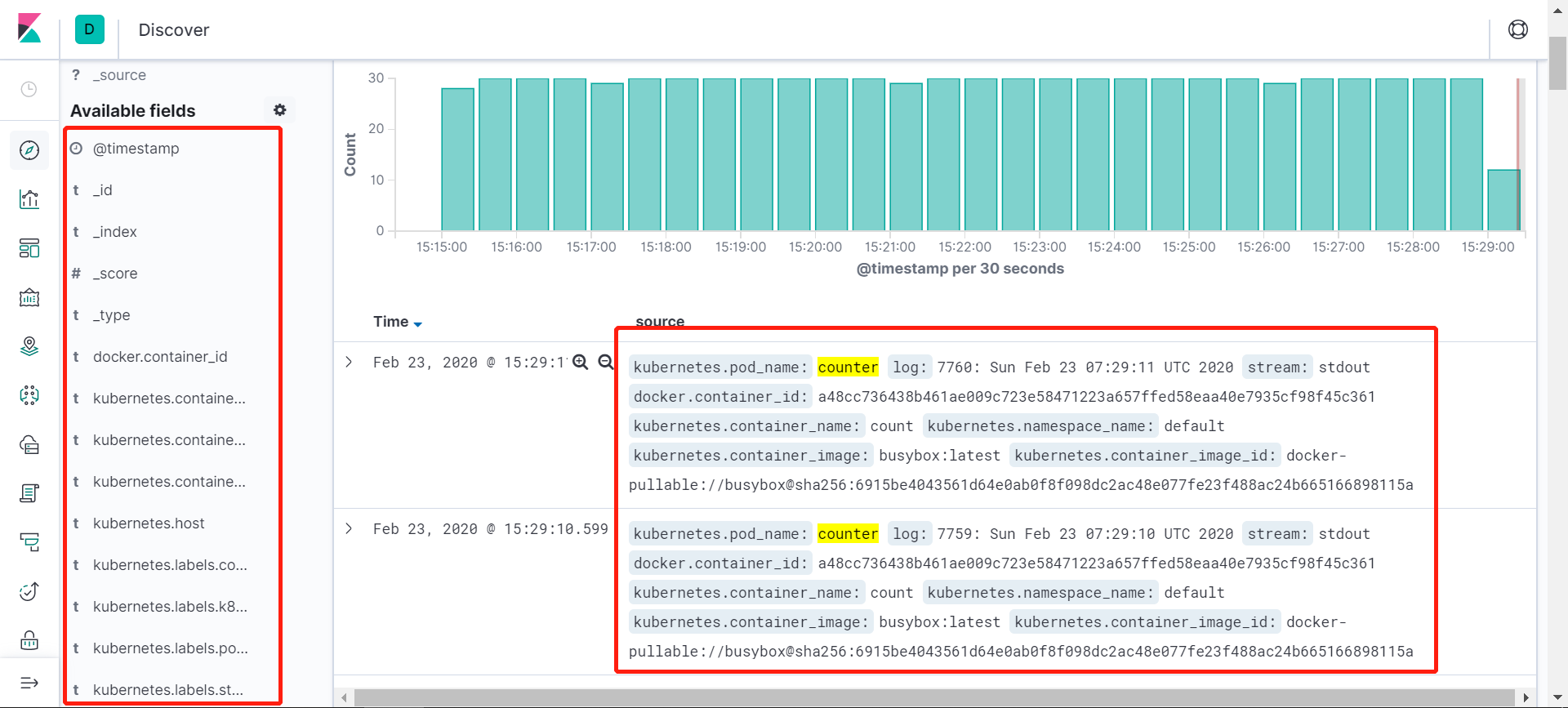
也可以通过其他元数据来过滤日志数据,比如可以单击任何日志条目以查看其他元数据,如容器名称,Kubernetes 节点,命名空间等,比如kubernetes.pod_name : counter
到这里,我们就在 Kubernetes 集群上成功部署了 EFK ,要了解如何使用 Kibana 进行日志数据分析,可以参考 Kibana 用户指南文档:https://www.elastic.co/guide/en/kibana/current/index.html
Prometheus实现k8s集群的服务监控
Prometheus 是一个开源监控系统,它本身已经成为了云原生中指标监控的事实标准 。
k8s集群监控体系演变史
第一版本:Cadvisor+InfluxDB+Grafana
只能从主机维度进行采集,没有Namespace、Pod等维度的汇聚功能
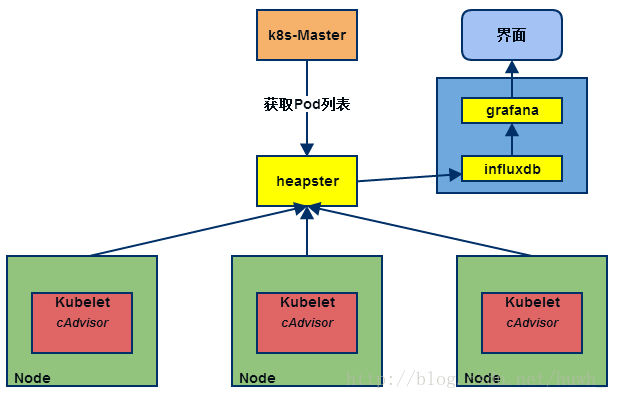
第二版本: Heapster+InfluxDB+Grafana
heapster负责调用各node中的cadvisor接口,对数据进行汇总,然后导到InfluxDB , 可以从cluster,node,pod的各个层面提供详细的资源使用情况。
第三版本:Metrics-Server + Prometheus
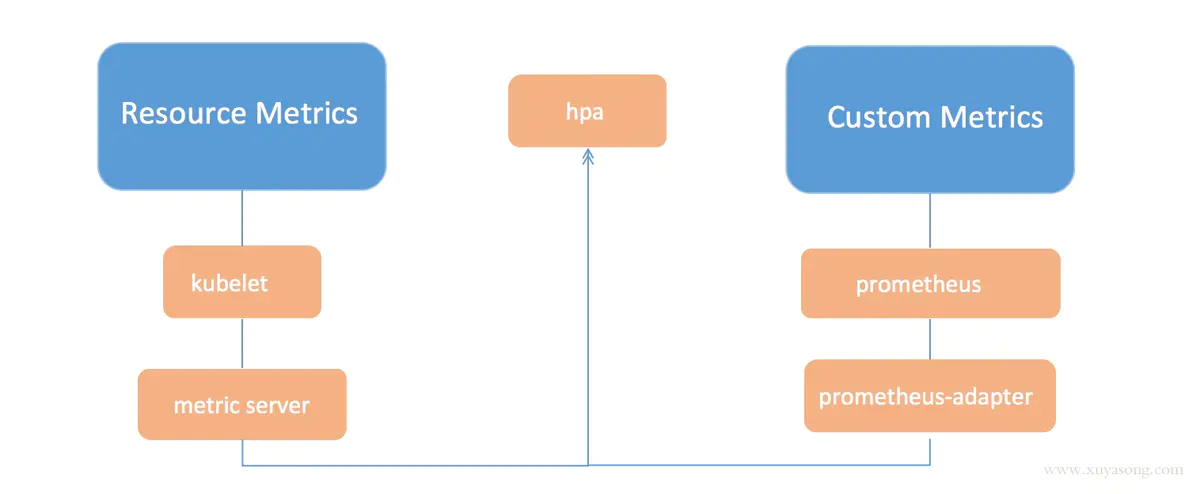
k8s对监控接口进行了标准化,主要分了三类:
-
Resource Metrics
对应的接口是 metrics.k8s.io,主要的实现就是 metrics-server,它提供的是资源的监控,比较常见的是节点级别、pod 级别、namespace 级别、class 级别。这类的监控指标都可以通过 metrics.k8s.io 这个接口获取到
-
Custom Metrics
对应的接口是 custom.metrics.k8s.io,主要的实现是 Prometheus, 它提供的是资源监控和自定义监控,资源监控和上面的资源监控其实是有覆盖关系的。
自定义监控指的是:比如应用上面想暴露一个类似像在线人数,或者说调用后面的这个数据库的 MySQL 的慢查询。这些其实都是可以在应用层做自己的定义的,然后并通过标准的 Prometheus 的 client,暴露出相应的 metrics,然后再被 Prometheus 进行采集
-
External Metrics
对应的接口是 external.metrics.k8s.io。主要的实现厂商就是各个云厂商的 provider,通过这个 provider 可以通过云资源的监控指标
Prometheus架构

- Prometheus Server ,监控、告警平台核心,抓取目标端监控数据,生成聚合数据,存储时间序列数据
- exporter,由被监控的对象提供,提供API暴漏监控对象的指标,供prometheus 抓取
- node-exporter
- blackbox-exporter
- redis-exporter
- mysql-exporter
- custom-exporter
- …
- pushgateway,提供一个网关地址,外部数据可以推送到该网关,prometheus也会从该网关拉取数据
- Alertmanager,接收Prometheus发送的告警并对于告警进行一系列的处理后发送给指定的目标
- Grafana:配置数据源,图标方式展示数据
Prometheus安装
基于go开发, https://github.com/prometheus/prometheus
若使用docker部署直接启动镜像即可:
$ docker run --name prometheus -d -p 127.0.0.1:9090:9090 prom/prometheus
我们想制作Prometheus的yaml文件,可以先启动容器进去看一下默认的启动命令:
$ docker run -d --name tmp -p 127.0.0.1:9090:9090 prom/prometheus:v2.19.2
$ docker exec -ti tmp sh
#/ ps aux
#/ cat /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself. exporter
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
本例中,使用k8s来部署,所需的资源清单如下:
# 创建新的命名空间 monitor,存储prometheus相关资源
$ cat prometheus-namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: monitor
# 需要准备配置文件,因此使用configmap的形式保存
$ cat prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# prometheus的资源文件
# 出现Prometheus数据存储权限问题,因为Prometheus内部使用nobody启动进程,挂载数据目录后权限为root,因此使用initContainer进行目录权限修复:
$ cat prometheus-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
nodeSelector:
app: prometheus
initContainers:
- name: "change-permission-of-directory"
image: busybox
command: ["/bin/sh"]
args: ["-c", "chown -R 65534:65534 /prometheus"]
securityContext:
privileged: true
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
containers:
- image: prom/prometheus:v2.19.2
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus" # 指定tsdb数据路径
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
- "--web.console.libraries=/usr/share/prometheus/console_libraries"
- "--web.console.templates=/usr/share/prometheus/consoles"
ports:
- containerPort: 9090
name: http
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
volumes:
- name: data
hostPath:
path: /data/prometheus/
- configMap:
name: prometheus-config
name: config-volume
# rbac,prometheus会调用k8s api做服务发现进行抓取指标
$ cat prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
# 提供Service,为Ingress使用
$ cat prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
app: prometheus
type: ClusterIP
ports:
- name: web
port: 9090
targetPort: http
$ cat prometheus-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus
namespace: monitor
spec:
rules:
- host: prometheus.luffy.com
http:
paths:
- path: /
backend:
serviceName: prometheus
servicePort: 9090
部署上述资源:
# 命名空间
$ kubectl create prometheus-namespace.yaml
# 给node打上label
$ kubectl label node k8s-slave1 app=prometheus
#部署configmap
$ kubectl create -f prometheus-configmap.yaml
# rbac
$ kubectl create -f prometheus-rbac.yaml
# deployment
$ kubectl create -f prometheus-deployment.yaml
# service
$ kubectl create -f prometheus-svc.yaml
# ingress
$ kubectl create -f prometheus-ingress.yaml
# 访问测试
$ kubectl -n monitor get ingress
理解时间序列数据库(TSDB)
# http://localhost:9090/metrics
$ kubectl -n monitor get po -o wide
prometheus-dcb499cbf-fxttx 1/1 Running 0 13h 10.244.1.132 k8s-slave1
$ curl http://10.244.1.132:9090/metrics
...
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 149
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
tsdb(Time Series Database)
其中#号开头的两行分别为:
- HELP开头说明该行为指标的帮助信息,通常解释指标的含义
- TYPE开头是指明了指标的类型
- counter 计数器
- guage 测量器
- histogram 柱状图
- summary 采样点分位图统计
其中非#开头的每一行表示当前采集到的一个监控样本:
- promhttp_metric_handler_requests_total表明了当前指标的名称
- 大括号中的标签则反映了当前样本的一些特征和维度
- 浮点数则是该监控样本的具体值。
每次采集到的数据都会被Prometheus以time-series(时间序列)的方式保存到内存中,定期刷新到硬盘。如下所示,可以将time-series理解为一个以时间为X轴的数字矩阵:
^
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . .
v
<------------------ 时间 ---------------->
在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):metric name和描述当前样本特征的labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个float64的浮点型数据表示当前样本的值。
在形式上,所有的指标(Metric)都通过如下格式标示:
<metric name>{<label name>=<label value>, ...}
- 指标的名称(metric name)可以反映被监控样本的含义(比如,
http_request_total- 表示当前系统接收到的HTTP请求总量)。 - 标签(label)反映了当前样本的特征维度,通过这些维度Prometheus可以对样本数据进行过滤,聚合等。
Prometheus:定期去Tragets列表拉取监控数据,存储到TSDB中,并且提供指标查询、分析的语句和接口。
添加监控目标
无论是业务应用还是k8s系统组件,只要提供了metrics api,并且该api返回的数据格式满足标准的Prometheus数据格式要求即可。
其实,很多组件已经为了适配Prometheus采集指标,添加了对应的/metrics api,比如
CoreDNS:
$ kubectl -n kube-system get po -owide|grep coredns
coredns-58cc8c89f4-nshx2 1/1 Running 6 22d 10.244.0.20
coredns-58cc8c89f4-t9h2r 1/1 Running 7 22d 10.244.0.21
$ curl 10.244.0.20:9153/metrics
修改target配置:
$ cat prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'coredns'
static_configs:
- targets: ['10.96.0.10:9153']
$ kubectl apply -f prometheus-configmap.yaml
# 重建pod生效
$ kubectl -n monitor delete po prometheus-dcb499cbf-fxttx
常用监控对象的指标采集
对于集群的监控一般我们需要考虑以下几个方面:
- 内部系统组件的状态:比如 kube-apiserver、kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 业务容器指标的监控(容器CPU、内存、磁盘等)
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标
监控kube-apiserver
apiserver自身也提供了/metrics 的api来提供监控数据,
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23d
$ curl -k -H "Authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6InhXcmtaSG5ZODF1TVJ6dUcycnRLT2c4U3ZncVdoVjlLaVRxNG1wZ0pqVmcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi10b2tlbi1xNXBueiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJhZG1pbiIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImViZDg2ODZjLWZkYzAtNDRlZC04NmZlLTY5ZmE0ZTE1YjBmMCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbiJ9.iEIVMWg2mHPD88GQ2i4uc_60K4o17e39tN0VI_Q_s3TrRS8hmpi0pkEaN88igEKZm95Qf1qcN9J5W5eqOmcK2SN83Dd9dyGAGxuNAdEwi0i73weFHHsjDqokl9_4RGbHT5lRY46BbIGADIphcTeVbCggI6T_V9zBbtl8dcmsd-lD_6c6uC2INtPyIfz1FplynkjEVLapp_45aXZ9IMy76ljNSA8Uc061Uys6PD3IXsUD5JJfdm7lAt0F7rn9SdX1q10F2lIHYCMcCcfEpLr4Vkymxb4IU4RCR8BsMOPIO_yfRVeYZkG4gU2C47KwxpLsJRrTUcUXJktSEPdeYYXf9w" https://172.21.51.67:6443/metrics
可以通过手动配置如下job来试下对apiserver服务的监控,
$ cat prometheus-configmap.yaml
...
- job_name: 'kubernetes-apiserver'
static_configs:
- targets: ['10.96.0.1']
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
监控集群节点基础指标
node_exporter https://github.com/prometheus/node_exporter
分析:
- 每个节点都需要监控,因此可以使用DaemonSet类型来管理node_exporter
- 添加节点的容忍配置
- 挂载宿主机中的系统文件信息
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.0.1
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations:
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
创建node-exporter服务
$ kubectl create -f node-exporter.yaml
$ kubectl -n monitor get po
问题来了,如何添加到Prometheus的target中?
- 配置一个Service,后端挂载node-exporter的服务,把Service的地址配置到target中
- 带来新的问题,target中无法直观的看到各节点node-exporter的状态
- 把每个node-exporter的服务都添加到target列表中
- 带来新的问题,集群节点的增删,都需要手动维护列表
- target列表维护量随着集群规模增加
Prometheus的服务发现与Relabeling
之前已经给Prometheus配置了RBAC,有读取node的权限,因此Prometheus可以去调用Kubernetes API获取node信息,所以Prometheus通过与 Kubernetes API 集成,提供了内置的服务发现分别是:Node、Service、Pod、Endpoints、Ingress
配置job即可:
- job_name: 'kubernetes-sd-node-exporter'
kubernetes_sd_configs:
- role: node
重建查看效果:
$ kubectl apply -f prometheus-configmap.yaml
$ kubectl -n monitor delete po prometheus-dcb499cbf-6cwlg
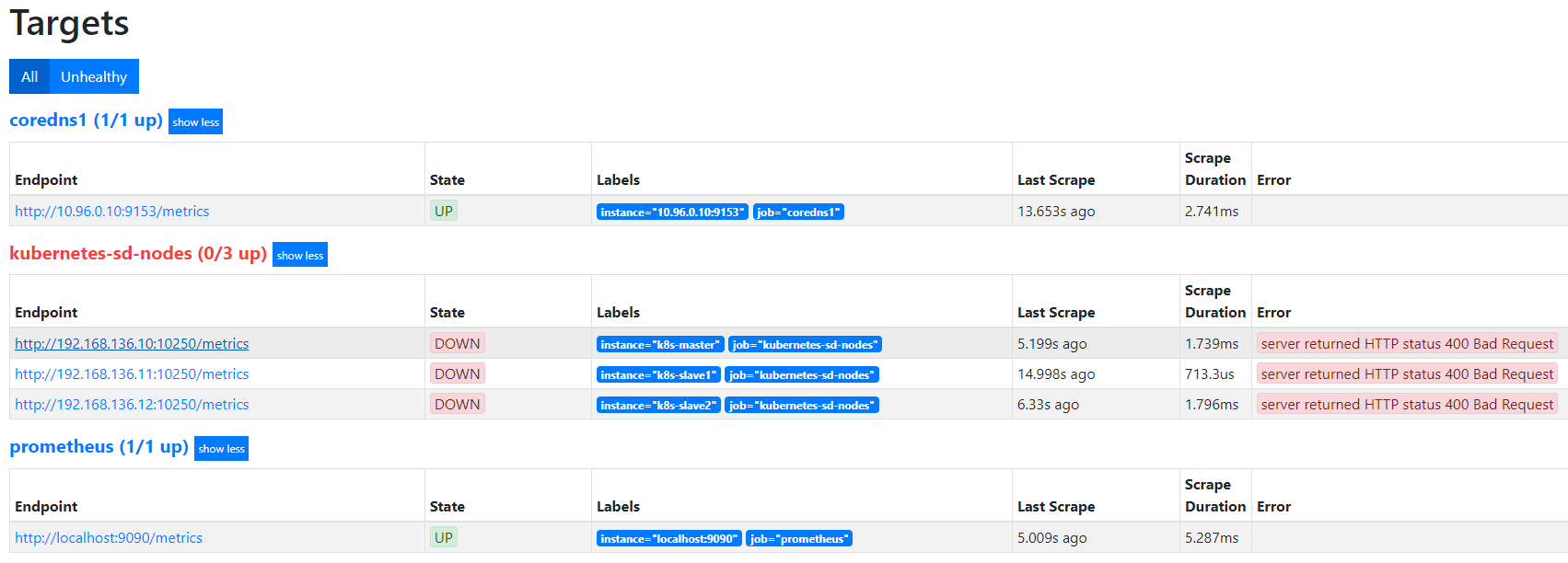
默认访问的地址是http://node-ip/10250/metrics,10250是kubelet API的服务端口,说明Prometheus的node类型的服务发现模式,默认是和kubelet的10250绑定的,而我们是期望使用node-exporter作为采集的指标来源,因此需要把访问的endpoint替换成http://node-ip:9100/metrics。

在真正抓取数据前,Prometheus提供了relabeling的能力。怎么理解?
查看Target的Label列,可以发现,每个target对应会有很多Before Relabeling的标签,这些__开头的label是系统内部使用,不会存储到样本的数据里,但是,我们在查看数据的时候,可以发现,每个数据都有两个默认的label,即:
prometheus_notifications_dropped_total{instance="localhost:9090",job="prometheus"}
instance的值其实则取自于__address__
这种发生在采集样本数据之前,对Target实例的标签进行重写的机制在Prometheus被称为Relabeling。
因此,利用relabeling的能力,只需要将__address__替换成node_exporter的服务地址即可。
- job_name: 'kubernetes-sd-node-exporter'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
再次更新Prometheus服务后,查看targets列表及node-exporter提供的指标,node_load1
使用cadvisor实现容器监控指标的采集(废弃)
cAdvisor 指标访问路径为 https://10.96.0.1/api/v1/nodes/<node_name>/proxy/metrics/cadvisor
https://10.96.0.1/api/v1/nodes/k8s-master/proxy/metrics/cadvisor
https://10.96.0.1/api/v1/nodes/k8s-slave1/proxy/metrics/cadvisor
https://10.96.0.1/api/v1/nodes/k8s-slave2/proxy/metrics/cadvisor
分析:
- 每个节点都需要做替换,可以利用Prometheus服务发现中
node这种role
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
默认添加的target列表为:__schema__://__address__ __metrics_path__
http://172.21.51.67:10250/metrics
http://172.21.51.68:10250/metrics
http://172.21.51.69:10250/metrics
-
抓取的地址是相同的,可以用
10.96.0.1做固定值进行替换__address__- job_name: 'kubernetes-sd-cadvisor' kubernetes_sd_configs: - role: node relabel_configs: - target_label: __address__ replacement: 10.96.0.1 action: replace目前为止,替换后的样子:
http://10.96.0.1/metrics http://10.96.0.1/metrics http://10.96.0.1/metrics -
需要把找到node-name,来做动态替换
__metrics_path__- job_name: 'kubernetes-sd-cadvisor' kubernetes_sd_configs: - role: node relabel_configs: - target_label: __address__ replacement: 10.96.0.1 action: replace - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor目前为止,替换后的样子:
http://10.96.0.1/api/v1/nodes/k8s-master/proxy/metrics/cadvisor http://10.96.0.1/api/v1/nodes/k8s-slave1/proxy/metrics/cadvisor http://10.96.0.1/api/v1/nodes/k8s-slave2/proxy/metrics/cadvisor -
加上api-server的认证信息
- job_name: 'kubernetes-sd-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt insecure_skip_verify: true bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - target_label: __address__ replacement: 10.96.0.1 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
重新应用配置,然后重建Prometheus的pod。查看targets列表,查看cadvisor指标,比如container_cpu_system_seconds_total,container_memory_usage_bytes
综上,利用node类型,可以实现对daemonset类型服务的目标自动发现以及监控数据抓取。
使用cadvisor实现容器指标的采集(新)
目前cAdvisor集成到了kubelet组件内 ,因此可以通过kubelet的接口实现容器指标的采集,具体的API为:
https://<node-ip>:10250/metrics/cadvisor # node上的cadvisor采集到的容器指标
https://<node-ip>:10250/metrics # node上的kubelet的指标数据
# 可以通过curl -k -H "Authorization: Bearer xxxx" https://xxxx/xx查看
因此,针对容器指标来讲,我们期望的采集target是:
https://172.21.51.67:10250/metrics/cadvisor
https://172.21.51.68:10250/metrics/cadvisor
https://172.21.51.69:10250/metrics/cadvisor
即每个node节点都需要去采集数据,联想到prometheus的服务发现中的node类型,因此,配置:
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
默认添加的target列表为:__schema__://__address__ __metrics_path__
http://172.21.51.67:10250/metrics
http://172.21.51.68:10250/metrics
http://172.21.51.69:10250/metrics
和期望值不同的是__schema__和__metrics_path__,针对__metrics_path__可以使用relabel修改:
relabel_configs:
- target_label: __metrics_path__
replacement: /metrics/cadvisor
针对__schema__:
- job_name: 'kubernetes-sd-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- target_label: __metrics_path__
replacement: /metrics/cadvisor
重新应用配置,然后重建Prometheus的pod。查看targets列表,查看cadvisor指标,比如container_cpu_system_seconds_total,container_memory_usage_bytes
综上,利用node类型,可以实现对daemonset类型服务的目标自动发现以及监控数据抓取。
补充:
若想采集kubelet的指标:
- job_name: 'kubernetes-sd-kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
集群Service服务的监控指标采集
比如集群中存在100个业务应用,每个业务应用都需要被Prometheus监控。
每个服务是不是都需要手动添加配置?有没有更好的方式?
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
添加到Prometheus配置中进行测试:
$ kubectl apply -f prometheus-configmap.yaml
$ kubectl -n monitor delete po prometheus-dcb499cbf-4h9qj
此使的Target列表中,kubernetes-sd-endpoints下出现了N多条数据,
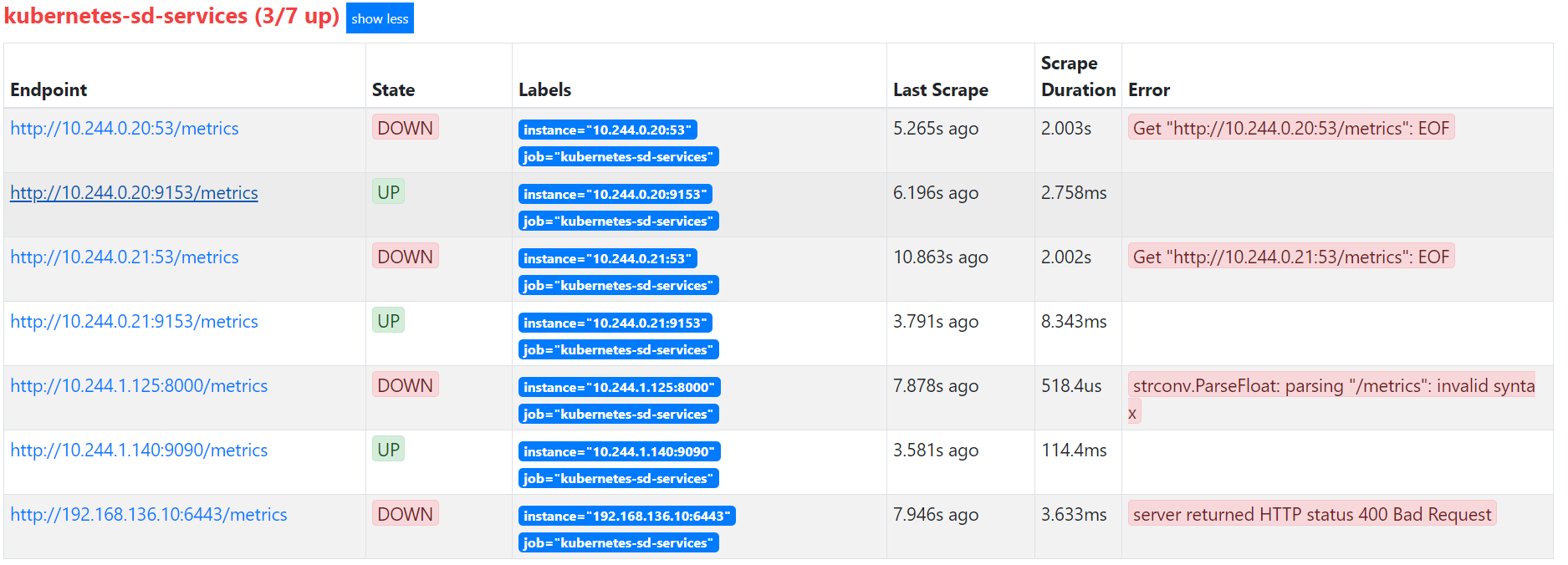
可以发现,实际上endpoint这个类型,目标是去抓取整个集群中所有的命名空间的Endpoint列表,然后使用默认的/metrics进行数据抓取,我们可以通过查看集群中的所有ep列表来做对比:
$ kubectl get endpoints --all-namespaces
但是实际上并不是每个服务都已经实现了/metrics监控的,也不是每个实现了/metrics接口的服务都需要注册到Prometheus中,因此,我们需要一种方式对需要采集的服务实现自主可控。这就需要利用relabeling中的keep功能。
我们知道,relabel的作用对象是target的Before Relabling标签,比如说,假如通过如下定义:
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__keep_this_service__]
action: keep
regex: “true”
那么就可以实现target的Before Relabling中若存在__keep_this_service__,且值为true的话,则会加入到kubernetes-endpoints这个target中,否则就会被删除。
因此可以为我们期望被采集的服务,加上对应的Prometheus的label即可。
问题来了,怎么加?
查看coredns的metrics类型Before Relabling中的值,可以发现,存在如下类型的Prometheus的标签:
__meta_kubernetes_service_annotation_prometheus_io_scrape="true"
__meta_kubernetes_service_annotation_prometheus_io_port="9153"
这些内容是如何生成的呢,查看coredns对应的服务属性:
$ kubectl -n kube-system get service kube-dns -oyaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
creationTimestamp: "2020-06-28T17:05:35Z"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: KubeDNS
name: kube-dns
namespace: kube-system
...
发现存在annotations声明,因此,可以联想到二者存在对应关系,Service的定义中的annotations里的特殊字符会被转换成Prometheus中的label中的下划线。
我们即可以使用如下配置,来定义服务是否要被抓取监控数据。
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
这样的话,我们只需要为服务定义上如下的声明,即可实现Prometheus自动采集数据
annotations:
prometheus.io/scrape: "true"
有些时候,我们业务应用提供监控数据的path地址并不一定是/metrics,如何实现兼容?
同样的思路,我们知道,Prometheus会默认使用Before Relabling中的__metrics_path作为采集路径,因此,我们再自定义一个annotation,prometheus.io/path
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/path/to/metrics"
这样,Prometheus端会自动生成如下标签:
__meta_kubernetes_service_annotation_prometheus_io_path="/path/to/metrics"
我们只需要在relabel_configs中用该标签的值,去重写__metrics_path__的值即可。因此:
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
有些时候,业务服务的metrics是独立的端口,比如coredns,业务端口是53,监控指标采集端口是9153,这种情况,如何处理?
很自然的,我们会想到通过自定义annotation来处理,
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/path/to/metrics"
prometheus.io/port: "9153"
如何去替换?
我们知道Prometheus默认使用Before Relabeling中的__address__进行作为服务指标采集的地址,但是该地址的格式通常是这样的
__address__="10.244.0.20:53"
__address__="10.244.0.21"
我们的目标是将如下两部分拼接在一起:
- 10.244.0.20
- prometheus.io/port定义的值,即
__meta_kubernetes_service_annotation_prometheus_io_port的值
因此,需要使用正则规则取出上述两部分:
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
需要注意的几点:
__address__中的:53有可能不存在,因此,使用()?的匹配方式进行- 表达式中,三段
()我们只需要第一和第三段,不需要中间括号部分的内容,因此使用?:的方式来做非获取匹配,即可以匹配内容,但是不会被记录到$1,$2这种变量中 - 多个source_labels中间默认使用
;号分割,因此匹配的时候需要注意添加;号
此外,还可以将before relabeling 中的更多常用的字段取出来添加到目标的label中,比如:
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
因此,目前的relabel的配置如下:
- job_name: 'kubernetes-sd-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
验证一下:
更新configmap并重启Prometheus服务,查看target列表。
kube-state-metrics监控
已经有了cadvisor,容器运行的指标已经可以获取到,但是下面这种情况却无能为力:
- 我调度了多少个replicas?现在可用的有几个?
- 多少个Pod是running/stopped/terminated状态?
- Pod重启了多少次?
而这些则是kube-state-metrics提供的内容,它基于client-go开发,轮询Kubernetes API,并将Kubernetes的结构化信息转换为metrics。因此,需要借助于kube-state-metrics来实现。
指标类别包括:
- CronJob Metrics
- DaemonSet Metrics
- Deployment Metrics
- Job Metrics
- LimitRange Metrics
- Node Metrics
- PersistentVolume Metrics
- PersistentVolumeClaim Metrics
- Pod Metrics
- kube_pod_info
- kube_pod_owner
- kube_pod_status_phase
- kube_pod_status_ready
- kube_pod_status_scheduled
- kube_pod_container_status_waiting
- kube_pod_container_status_terminated_reason
- …
- Pod Disruption Budget Metrics
- ReplicaSet Metrics
- ReplicationController Metrics
- ResourceQuota Metrics
- Service Metrics
- StatefulSet Metrics
- Namespace Metrics
- Horizontal Pod Autoscaler Metrics
- Endpoint Metrics
- Secret Metrics
- ConfigMap Metrics
部署: https://github.com/kubernetes/kube-state-metrics#kubernetes-deployment
$ wget https://github.com/kubernetes/kube-state-metrics/archive/v1.9.7.tar.gz
$ tar zxf v1.9.7.tar.gz
$ cp -r kube-state-metrics-1.9.7/examples/standard/ .
$ ll standard/
total 20
-rw-r--r-- 1 root root 377 Jul 24 06:12 cluster-role-binding.yaml
-rw-r--r-- 1 root root 1651 Jul 24 06:12 cluster-role.yaml
-rw-r--r-- 1 root root 1069 Jul 24 06:12 deployment.yaml
-rw-r--r-- 1 root root 193 Jul 24 06:12 service-account.yaml
-rw-r--r-- 1 root root 406 Jul 24 06:12 service.yaml
# 替换namespace为monitor
$ sed -i 's/namespace: kube-system/namespace: monitor/g' standard/*
$ kubectl create -f standard/
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
service/kube-state-metrics created
如何添加到Prometheus监控target中?
$ cat standard/service.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
labels:
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: v1.9.7
name: kube-state-metrics
namespace: monitor
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
$ kubectl apply -f standard/service.yaml
查看target列表,观察是否存在kube-state-metrics的target。
kube_pod_container_status_running
kube_deployment_status_replicas
Grafana
可视化面板,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
安装
注意点:
- 使用最新版本的镜像 https://github.com/grafana/grafana
- 通过环境变量设置管理员账户密码
- GF_SECURITY_ADMIN_USER
- GF_SECURITY_ADMIN_PASSWORD
- 通过设置securityContext的方式让grafana进程使用root启动
- 数据挂载到本地
- 配置ingress暴露访问入口
$ cat grafana-all.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitor
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
hostPath:
path: /data/grafana/
nodeSelector:
app: prometheus
securityContext:
runAsUser: 0
containers:
- name: grafana
image: grafana/grafana:7.1.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 150m
memory: 512Mi
requests:
cpu: 150m
memory: 512Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitor
spec:
type: ClusterIP
ports:
- port: 3000
selector:
app: grafana
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: monitor
spec:
rules:
- host: grafana.luffy.com
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000
配置数据源:
- URL:http://prometheus:9090
如何丰富Grafana监控面板:
- 导入dashboard
- 安装相应的插件
- 自定义监控面板
导入Dashboard的配置
dashboard: https://grafana.com/grafana/dashboards
- Node Exporter https://grafana.com/grafana/dashboards/8919
- Prometheus: https://grafana.com/grafana/dashboards/8588
DevOpsProdigy KubeGraf插件的使用
除了直接导入Dashboard,我们还可以通过安装插件的方式获得,Configuration -> Plugins可以查看已安装的插件,通过 官方插件列表 我们可以获取更多可用插件。
Kubernetes相关的插件:
DevOpsProdigy KubeGraf 是一个非常优秀的 Grafana Kubernetes 插件,是 Grafana 官方的 Kubernetes 插件的升级版本,该插件可以用来可视化和分析 Kubernetes 集群的性能,通过各种图形直观的展示了 Kubernetes 集群的主要服务的指标和特征,还可以用于检查应用程序的生命周期和错误日志。
# 进入grafana容器内部执行安装
$ kubectl -n monitor exec -ti grafana-594f447d6c-jmjsw bash
bash-5.0# grafana-cli plugins install devopsprodigy-kubegraf-app 1.4.1
installing devopsprodigy-kubegraf-app @ 1.4.1
from: https://grafana.com/api/plugins/devopsprodigy-kubegraf-app/versions/1.4.1/download
into: /var/lib/grafana/plugins
✔ Installed devopsprodigy-kubegraf-app successfully
Restart grafana after installing plugins . <service grafana-server restart>
bash-5.0# grafana-cli plugins install grafana-piechart-panel
installing grafana-piechart-panel @ 1.5.0
from: https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.5.0/download
into: /var/lib/grafana/plugins
✔ Installed grafana-piechart-panel successfully
Restart grafana after installing plugins . <service grafana-server restart>
# 也可以下载离线包进行安装
# 重建pod生效
$ kubectl -n monitor delete po grafana-594f447d6c-jmjsw
登录grafana界面,Configuration -> Plugins 中找到安装的插件,点击插件进入插件详情页面,点击 [Enable]按钮启用插件,点击 Set up your first k8s-cluster 创建一个新的 Kubernetes 集群:
-
Name:luffy-k8s
-
URL:https://kubernetes.default:443
-
Access:使用默认的Server(default)
-
Skip TLS Verify:勾选,跳过证书合法性校验
-
Auth:勾选TLS Client Auth以及With CA Cert,勾选后会下面有三块证书内容需要填写,内容均来自
~/.kube/config文件,需要对文件中的内容做一次base64 解码- CA Cert:使用config文件中的
certificate-authority-data对应的内容 - Client Cert:使用config文件中的
client-certificate-data对应的内容 - Client Key:使用config文件中的
client-key-data对应的内容
- CA Cert:使用config文件中的
自定义监控面板
通用的监控需求基本上都可以使用第三方的Dashboard来解决,对于业务应用自己实现的指标的监控面板,则需要我们手动进行创建。
调试Panel:直接输入Metrics,查询数据。
如,输入node_load1来查看集群节点最近1分钟的平均负载,直接保存即可生成一个panel
如何根据字段过滤,实现联动效果?
比如想实现根据集群节点名称进行过滤,可以通过如下方式:
-
设置 -> Variables -> Add Variable,添加一个变量node,
- Name:node
- Label:选择节点
- Data Source:Prometheus
- Query:kube_node_info,可以在页面下方的
Preview of values查看到当前变量的可选值 - Regex:
/.*node=\"(.+?)\".*/ - Refresh:
On Dashboard Load - Multi-value:true
- Include All Options:true
-
修改Metrics,$node和变量名字保持一致,意思为自动读取当前设置的节点的名字
node_load1{instance=~"$node"}
再添加一个面板,使用如下的表达式:
100-avg(irate(node_cpu_seconds_total{mode="idle",instance=~"$node"}[5m])) by (instance)*100
Metrics指标类型与PromQL
TSDB的样本分布示意图:
^
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . . node_cpu_seconds_total{...}
v
<------------------ 时间 ---------------->
Guage类型:
$ kubectl -n monitor get po -o wide |grep k8s-master
node-exporter-ld6sq 1/1 Running 0 4d3h 172.21.51.67 k8s-master
$ curl -s 172.21.51.67:9100/metrics |grep node_load1
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.18
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.37
Gauge类型的指标侧重于反应系统的当前状态。
- 这类指标的样本数据可增可减。
- 常见指标如:node_memory_MemAvailable_bytes(可用内存大小)、node_load1(系统平均负载)
Guage类型的数据,通常直接查询就会有比较直观的业务含义,比如:
- node_load5
- node_memory_MemAvailable_bytes
我们也会对这类数据做简单的处理,比如:
- 过滤其中某些节点
- 对指标进行数学运算
这就是PromQL提供的能力,可以对收集到的数据做聚合、计算等处理。
PromQL( Prometheus Query Language )是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。
比如:
-
只显示k8s-master节点的平均负载
node_load1{instance="k8s-master"} -
显示除了k8s-master节点外的其他节点的平均负载
node_load1{instance!="k8s-master"} -
正则匹配
node_load1{instance=~"k8s-master|k8s-slave1"} -
集群各节点系统内存使用率
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes) / node_memory_MemTotal_bytes
counter类型:
$ curl -s 172.21.51.67:9100/metrics |grep node_cpu_seconds_total
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 294341.02
node_cpu_seconds_total{cpu="0",mode="iowait"} 120.78
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.13
node_cpu_seconds_total{cpu="0",mode="softirq"} 1263.29
counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu_seconds_total都是Counter类型的监控指标。
通常计数器类型的指标,名称后面都以_total结尾。我们通过理解CPU利用率的PromQL表达式来讲解Counter指标类型的使用。
各节点CPU的平均使用率表达式:
(1- sum(increase(node_cpu_seconds_total{mode="idle"}[2m])) by (instance) / sum(increase(node_cpu_seconds_total{}[2m])) by (instance)) * 100
分析:
node_cpu_seconds_total的指标含义是统计系统运行以来,CPU资源分配的时间总数,单位为秒,是累加的值。比如,直接运行该指标:
node_cpu_seconds_total
# 显示的是所有节点、所有CPU核心、在各种工作模式下分配的时间总和
其中mode的值和我们平常在系统中执行top命令看到的CPU显示的信息一致:
每个mode对应的含义如下:
user(us) 表示用户态空间或者说是用户进程(running user space processes)使用CPU所耗费的时间。这是日常我们部署的应用所在的层面,最常见常用。system(sy) 表示内核态层级使用CPU所耗费的时间。分配内存、IO操作、创建子进程……都是内核操作。这也表明,当IO操作频繁时,System参数会很高。steal(st) 当运行在虚拟化环境中,花费在其它 OS 中的时间(基于虚拟机监视器 hypervisor 的调度);可以理解成由于虚拟机调度器将 cpu 时间用于其它 OS 了,故当前 OS 无法使用 CPU 的时间。softirq(si) 从系统启动开始,累计到当前时刻,软中断时间irq(hi) 从系统启动开始,累计到当前时刻,硬中断时间nice(ni) 从系统启动开始,累计到当前时刻, 低优先级(低优先级意味着进程 nice 值小于 0)用户态的进程所占用的CPU时间iowait(wa) 从系统启动开始,累计到当前时刻,IO等待时间idle(id) 从系统启动开始,累计到当前时刻,除IO等待时间以外的其它等待时间,亦即空闲时间
我们通过指标拿到的各核心cpu分配的总时长数据,都是瞬时的数据,如何转换成 CPU的利用率?
先来考虑如何我们如何计算CPU利用率,假如我的k8s-master节点是4核CPU,我们来考虑如下场景:
- 过去1分钟内每个CPU核心处于idle状态的时长,假如分别为 :
- cpu0:20s
- cpu1:30s
- cpu2:50s
- cpu3:40s
- 则四个核心总共可分配的时长是 4*60=240s
- 实际空闲状态的总时长为20+30+50+40=140s
- 那么我们可以计算出过去1分钟k8s-master节点的CPU利用率为 (1- 140/240) * 100 = 41.7%
因此,我们只需要使用PromQL取出上述过程中的值即可:
# 过滤出当前时间点idle的时长
node_cpu_seconds_total{mode="idle"}
# 使用[1m]取出1分钟区间内的样本值,注意,1m区间要大于prometheus设置的抓取周期,此处会将周期内所以的样本值取出
node_cpu_seconds_total{mode="idle"}[1m]
# 使用increase方法,获取该区间内idle状态的增量值,即1分钟内,mode="idle"状态增加的时长
increase(node_cpu_seconds_total{mode="idle"}[1m])
# 由于是多个cpu核心,因此需要做累加,使用sum函数
sum(increase(node_cpu_seconds_total{mode="idle"}[1m]))
# 由于是多台机器,因此,需要按照instance的值进行分组累加,使用by关键字做分组,这样就获得了1分钟内,每个节点上 所有CPU核心idle状态的增量时长,即前面示例中的”20+30+50+40=140s“
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
# 去掉mode=idle的过滤条件,即可获取1分钟内,所有状态的cpu获得的增量总时长,即4*60=240s
sum(increase(node_cpu_seconds_total{}[1m])) by (instance)
# 最终的语句
(1- sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total{}[1m])) by (instance)) * 100
除此之外,还会经常看到irate和rate方法的使用:
irate() 是基于最后两个数据点计算一个时序指标在一个范围内的每秒递增率 ,举个例子:
# 1min内,k8s-master节点的idle状态的cpu分配时长增量值
increase(node_cpu_seconds_total{instance="k8s-master",mode="idle"}[1m])
{cpu="0",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 56.5
{cpu="1",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 56.04
{cpu="2",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 56.6
{cpu="3",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 56.5
#以第一条数据为例,说明过去的1分钟,k8s-master节点的第一个CPU核心,有56.5秒的时长是出于idle状态的
# 1min内,k8s-master节点的idle状态的cpu分配每秒的速率
irate(node_cpu_seconds_total{instance="k8s-master",mode="idle"}[1m])
{cpu="0",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.934
{cpu="1",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.932
{cpu="2",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.933
{cpu="3",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.936
# 该值如何计算的?
# irate会取出样本中的最后两个点来作为增长依据,然后做差值计算,并且除以两个样本间的数据时长,也就是说,我们设置2m,5m取出来的值是一样的,因为只会计算最后两个样本差。
# 以第一条数据为例,表示用irate计算出来的结果是,过去的两分钟内,cpu平均每秒钟有0.934秒的时间是处于idle状态的
# rate会1min内第一个和最后一个样本值为依据,计算方式和irate保持一致
rate(node_cpu_seconds_total{instance="k8s-master",mode="idle"}[1m])
{cpu="0",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.933
{cpu="1",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.940
{cpu="2",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.935
{cpu="3",instance="k8s-master",job="kubernetes-sd-node-exporter",mode="idle"} 0.937
因此rate的值,相对来讲更平滑,因为计算的是时间段内的平均,更适合于用作告警。
Alertmanager
Alertmanager是一个独立的告警模块。
-
接收Prometheus等客户端发来的警报
-
通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;
-
告警方式可以按照不同的规则发送给不同的模块负责人。Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
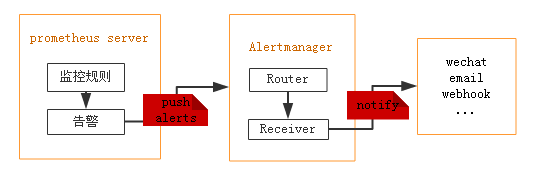
如果集群主机的内存使用率超过80%,且该现象持续了2分钟?想实现这样的监控告警,如何做?
从上图可得知设置警报和通知的主要步骤是:
-
安装和配置 Alertmanager
-
配置Prometheus与Alertmanager对话
-
在Prometheus中创建警报规则
安装
Alertmanager, https://github.com/prometheus/alertmanager#install
./alertmanager --config.file=config.yml
alertmanager.yml配置文件格式:
$ cat alertmanager-config.yml
apiVersion: v1
data:
config.yml: |
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'earlene163@163.com'
smtp_auth_username: 'earlene163@163.com'
smtp_auth_password: 'qzpm10'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 接收到的报警信息里面有许多alertname=NodeLoadHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送
group_wait: 30s
# 相同的group发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送
repeat_interval: 1m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- {}
# 配置告警接收者的信息
receivers:
- name: 'default'
email_configs:
- to: '654147123@qq.com'
send_resolved: true # 接受告警恢复的通知
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
主要配置的作用:
- global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
- route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
- receivers: 配置告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式。
配置文件:
$ kubectl create -f alertmanager-config.yml
其他资源清单文件:
$ cat alertmanager-all.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
app: alertmanager
spec:
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
volumes:
- name: config
configMap:
name: alertmanager
containers:
- name: alertmanager
image: prom/alertmanager:v0.21.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: config
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitor
spec:
type: ClusterIP
ports:
- port: 9093
selector:
app: alertmanager
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: alertmanager
namespace: monitor
spec:
rules:
- host: alertmanager.luffy.com
http:
paths:
- path: /
backend:
serviceName: alertmanager
servicePort: 9093
配置Prometheus与Alertmanager对话
是否告警是由Prometheus进行判断的,若有告警产生,Prometheus会将告警push到Alertmanager,因此,需要在Prometheus端配置alertmanager的地址:
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
因此,修改Prometheus的配置文件,然后重新加载pod
# 编辑prometheus-configmap.yaml配置,添加alertmanager内容
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
...
$ kubectl apply -f prometheus-configmap.yaml
# 现在已经有监控数据了,因此使用prometheus提供的reload的接口,进行服务重启
# 查看配置文件是否已经自动加载到pod中
$ kubectl -n monitor get po -o wide
prometheus-dcb499cbf-pljfn 1/1 Running 0 47h 10.244.1.167
$ kubectl -n monitor exec -ti prometheus-dcb499cbf-pljfn cat /etc/prometheus/prometheus.yml |grep alertmanager
# 使用软加载的方式,
$ curl -X POST 10.244.1.167:9090/-/reload
配置报警规则
目前Prometheus与Alertmanager已经连通,接下来我们可以针对收集到的各类指标配置报警规则,一旦满足报警规则的设置,则Prometheus将报警信息推送给Alertmanager,进而转发到我们配置的邮件中。
在哪里配置?同样是在prometheus-configmap中:
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /etc/prometheus/alert_rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
...
rules.yml我们同样使用configmap的方式挂载到prometheus容器内部,因此只需要在已有的configmap中加一个数据项目
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /etc/prometheus/alert_rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
... # 省略中间部分
alert_rules.yml: |
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1
for: 2m
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"
告警规则的几个要素:
group.name:告警分组的名称,一个组下可以配置一类告警规则,比如都是物理节点相关的告警alert:告警规则的名称expr:是用于进行报警规则 PromQL 查询语句,expr通常是布尔表达式,可以让Prometheus根据计算的指标值做 true or false 的判断for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending,屏蔽掉瞬时的问题,把焦点放在真正有持续影响的问题上labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上,可以用于后面做路由判断,通知到不同的终端,通常被用于添加告警级别的标签annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的
规则配置中,支持模板的方式,其中:
-
{{$labels}}可以获取当前指标的所有标签,支持{{$labels.instance}}或者{{$labels.job}}这种形式
-
{{ $value }}可以获取当前计算出的指标值
更新配置并软重启,并查看Prometheus报警规则。
一个报警信息在生命周期内有下面3种状态:
inactive: 表示当前报警信息处于非活动状态,即不满足报警条件pending: 表示在设置的阈值时间范围内被激活了,即满足报警条件,但是还在观察期内firing: 表示超过设置的阈值时间被激活了,即满足报警条件,且报警触发时间超过了观察期,会发送到Alertmanager端
对于已经 pending 或者 firing 的告警,Prometheus 也会将它们存储到时间序列ALERTS{}中。当然我们也可以通过表达式去查询告警实例:
ALERTS{}
查看Alertmanager日志:
level=warn ts=2020-07-28T13:43:59.430Z caller=notify.go:674 component=dispatcher receiver=email integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="*email.loginAuth auth: 550 User has no permission"
说明告警已经推送到Alertmanager端了,但是邮箱登录的时候报错,这是因为邮箱默认没有开启第三方客户端登录。因此需要登录163邮箱设置SMTP服务允许客户端登录。
自定义webhook实现告警消息的推送
目前官方内置的第三方通知集成包括:邮件、 即时通讯软件(如Slack、Hipchat)、移动应用消息推送(如Pushover)和自动化运维工具(例如:Pagerduty、Opsgenie、Victorops)。可以在alertmanager的管理界面中查看到。
每一个receiver具有一个全局唯一的名称,并且对应一个或者多个通知方式:
name: <string>
email_configs:
[ - <email_config>, ... ]
hipchat_configs:
[ - <hipchat_config>, ... ]
slack_configs:
[ - <slack_config>, ... ]
opsgenie_configs:
[ - <opsgenie_config>, ... ]
webhook_configs:
[ - <webhook_config>, ... ]
如果想实现告警消息推送给企业常用的即时聊天工具,如钉钉或者企业微信,如何配置?
Alertmanager的通知方式中还可以支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持。
# 警报接收者
receivers:
#ops
- name: 'demo-webhook'
webhook_configs:
- send_resolved: true
url: http://demo-webhook/alert/send
当我们配置了上述webhook地址,则当告警路由到demo-webhook时,alertmanager端会向webhook地址推送POST请求:
$ curl -X POST -d"$demoAlerts" http://demo-webhook/alert/send
$ echo $demoAlerts
{
"version": "4",
"groupKey": <string>, alerts (e.g. to deduplicate) ,
"status": "<resolved|firing>",
"receiver": <string>,
"groupLabels": <object>,
"commonLabels": <object>,
"commonAnnotations": <object>,
"externalURL": <string>, // backlink to the Alertmanager.
"alerts":
[{
"labels": <object>,
"annotations": <object>,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>"
}]
}
因此,假如我们想把报警消息自动推送到钉钉群聊,只需要:
- 实现一个webhook,部署到k8s集群
- 接收POST请求,将Alertmanager传过来的数据做解析,调用dingtalk的API,实现消息推送
- 配置alertmanager的receiver为webhook地址
如何给钉钉群聊发送消息? 钉钉机器人
钉钉群聊机器人设置:
每个群聊机器人在创建的时候都会生成唯一的一个访问地址:
https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a
这样,我们就可以使用如下方式来模拟给群聊机器人发送请求,实现消息的推送:
curl 'https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text","text": {"content": "我就是我, 是不一样的烟火"}}'
https://gitee.com/agagin/prometheus-webhook-dingtalk
镜像地址:timonwong/prometheus-webhook-dingtalk:master
二进制运行:
$ ./prometheus-webhook-dingtalk --config.file=config.yml
假如使用如下配置:
targets:
webhook_dev:
url: https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a
webhook_ops:
url: https://oapi.dingtalk.com/robot/send?access_token=d4e7b72eab6d1b2245bc0869d674f627dc187577a3ad485d9c1d131b7d67b15b
则prometheus-webhook-dingtalk启动后会自动支持如下API的POST访问:
http://locahost:8060/dingtalk/webhook_dev/send
http://localhost:8060/dingtalk/webhook_ops/send
这样可以使用一个prometheus-webhook-dingtalk来实现多个钉钉群的webhook地址
部署prometheus-webhook-dingtalk,从Dockerfile可以得知需要注意的点:
- 默认使用配置文件
/etc/prometheus-webhook-dingtalk/config.yml,可以通过configmap挂载 - 该目录下还有模板文件,因此需要使用subpath的方式挂载
- 部署Service,作为Alertmanager的默认访问,服务端口默认8060
配置文件:
$ cat webhook-dingtalk-configmap.yaml
apiVersion: v1
data:
config.yml: |
targets:
webhook_dev:
url: https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a
kind: ConfigMap
metadata:
name: webhook-dingtalk-config
namespace: monitor
Deployment和Service
$ cat webhook-dingtalk-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: webhook-dingtalk
namespace: monitor
spec:
selector:
matchLabels:
app: webhook-dingtalk
template:
metadata:
labels:
app: webhook-dingtalk
spec:
containers:
- name: webhook-dingtalk
image: timonwong/prometheus-webhook-dingtalk:master
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: "/etc/prometheus-webhook-dingtalk/config.yml"
name: config
subPath: config.yml
ports:
- containerPort: 8060
name: http
resources:
requests:
cpu: 50m
memory: 100Mi
limits:
cpu: 50m
memory: 100Mi
volumes:
- name: config
configMap:
name: webhook-dingtalk-config
items:
- key: config.yml
path: config.yml
---
apiVersion: v1
kind: Service
metadata:
name: webhook-dingtalk
namespace: monitor
spec:
selector:
app: webhook-dingtalk
ports:
- name: hook
port: 8060
targetPort: http
创建:
$ kubectl create -f webhook-dingtalk-configmap.yaml
$ kubectl create -f webhook-dingtalk-deploy.yaml
# 查看日志,可以得知当前的可用webhook日志
$ kubectl -n monitor logs -f webhook-dingtalk-f7f5589c9-qglkd
...
file=/etc/prometheus-webhook-dingtalk/config.yml msg="Completed loading of configuration file"
level=info ts=2020-07-30T14:05:40.963Z caller=main.go:117 component=configuration msg="Loading templates" templates=
ts=2020-07-30T14:05:40.963Z caller=main.go:133 component=configuration msg="Webhook urls for prometheus alertmanager" urls="http://localhost:8060/dingtalk/webhook_dev/send http://localhost:8060/dingtalk/webhook_ops/send"
level=info ts=2020-07-30T14:05:40.963Z caller=web.go:210 component=web msg="Start listening for connections" address=:8060
修改Alertmanager路由及webhook配置:
$ cat alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
data:
config.yml: |-
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'earlene163@163.com'
smtp_auth_username: 'earlene163@163.com'
# 注意这里不是邮箱密码,是邮箱开启第三方客户端登录后的授权码
smtp_auth_password: 'GXIWNXKMMEVMNHAJ'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 按照告警名称分组
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 10m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 路由树,默认继承global中的配置,并且可以在每个子路由上进行覆盖。
routes:
- {}
receivers:
- name: 'default'
email_configs:
- to: '654147123@qq.com'
send_resolved: true # 接受告警恢复的通知
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_dev/send
验证钉钉消息是否正常收到。
基于Label的动态告警处理
真实的场景中,我们往往期望可以给告警设置级别,而且可以实现不同的报警级别可以由不同的receiver接收告警消息。
Alertmanager中路由负责对告警信息进行分组匹配,并向告警接收器发送通知。告警接收器可以通过以下形式进行配置:
routes:
- receiver: ops
group_wait: 10s
match:
severity: critical
- receiver: dev
group_wait: 10s
match_re:
severity: normal|middle
receivers:
- ops
...
- dev
...
- <receiver> ...
因此可以为了更全面的感受报警的逻辑,我们再添加两个报警规则:
alert_rules.yml: |
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1
for: 2m
labels:
severity: normal
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 40
for: 2m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 40% (current value is: {{ $value }}"
- name: targets_status
rules:
- alert: TargetStatus
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "{{$labels.instance}}: prometheus target down"
description: "{{$labels.instance}}: prometheus target down,job is {{$labels.job}}"
我们为不同的报警规则设置了不同的标签,如severity: critical,针对规则中的label,来配置alertmanager路由规则,实现转发给不同的接收者。
$ cat alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
data:
config.yml: |-
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'earlene163@163.com'
smtp_auth_username: 'earlene163@163.com'
# 注意这里不是邮箱密码,是邮箱开启第三方客户端登录后的授权码
smtp_auth_password: 'RMAOPQVHKLPYFVHZ'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 按照告警名称分组
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 1m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 路由树,默认继承global中的配置,并且可以在每个子路由上进行覆盖。
routes:
- receiver: critical_alerts
group_wait: 10s
match:
severity: critical
- receiver: normal_alerts
group_wait: 10s
match_re:
severity: normal|middle
receivers:
- name: 'default'
email_configs:
- to: '654147123@qq.com'
send_resolved: true # 接受告警恢复的通知
- name: 'critical_alerts'
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_ops/send
- name: 'normal_alerts'
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_dev/send
再配置一个钉钉机器人,修改webhook-dingtalk的配置,添加webhook_ops的配置:
$ cat webhook-dingtalk-configmap.yaml
apiVersion: v1
data:
config.yml: |
targets:
webhook_dev:
url: https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a
webhook_ops:
url: https://oapi.dingtalk.com/robot/send?access_token=5a68888fbecde75b1832ff024d7374e51f2babd33f1078e5311cdbb8e2c00c3a
kind: ConfigMap
metadata:
name: webhook-dingtalk-config
namespace: monitor
设置webhook-dingtalk开启lifecycle
分别更新Prometheus和Alertmanager配置,查看报警的发送。
抑制和静默
前面我们知道,告警的group(分组)功能通过把多条告警数据聚合,有效的减少告警的频繁发送。除此之外,Alertmanager还支持Inhibition(抑制) 和 Silences(静默),帮助我们抑制或者屏蔽报警。
-
Inhibition 抑制
抑制是当出现其它告警的时候压制当前告警的通知,可以有效的防止告警风暴。
比如当机房出现网络故障时,所有服务都将不可用而产生大量服务不可用告警,但这些警告并不能反映真实问题在哪,真正需要发出的应该是网络故障告警。当出现网络故障告警的时候,应当抑制服务不可用告警的通知。
在Alertmanager配置文件中,使用inhibit_rules定义一组告警的抑制规则:
inhibit_rules: [ - <inhibit_rule> ... ]每一条抑制规则的具体配置如下:
target_match: [ <labelname>: <labelvalue>, ... ] target_match_re: [ <labelname>: <regex>, ... ] source_match: [ <labelname>: <labelvalue>, ... ] source_match_re: [ <labelname>: <regex>, ... ] [ equal: '[' <labelname>, ... ']' ]当已经发送的告警通知匹配到target_match或者target_match_re规则,当有新的告警规则如果满足source_match或者定义的匹配规则,并且已发送的告警与新产生的告警中equal定义的标签完全相同,则启动抑制机制,新的告警不会发送。
例如,定义如下抑制规则:
- source_match: alertname: NodeDown severity: critical target_match: severity: critical equal: - node如当集群中的某一个主机节点异常宕机导致告警NodeDown被触发,同时在告警规则中定义了告警级别severity=critical。由于主机异常宕机,该主机上部署的所有服务,中间件会不可用并触发报警。根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签node的值与NodeDown告警的相同,则说明新的告警是由NodeDown导致的,则启动抑制机制停止向接收器发送通知。
演示:实现如果 NodeMemoryUsage 报警触发,则抑制NodeLoad指标规则引起的报警。
inhibit_rules: - source_match: alertname: NodeMemoryUsage severity: critical target_match: severity: normal equal: - instance -
Silences: 静默
简单直接的在指定时段关闭告警。静默通过匹配器(Matcher)来配置,类似于路由树。警告进入系统的时候会检查它是否匹配某条静默规则,如果是则该警告的通知将忽略。 静默规则在Alertmanager的 Web 界面里配置。
一条告警产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。这个过程中可能会因为各种原因会导致告警产生了却最终没有进行通知,可以通过下图了解整个告警的生命周期:
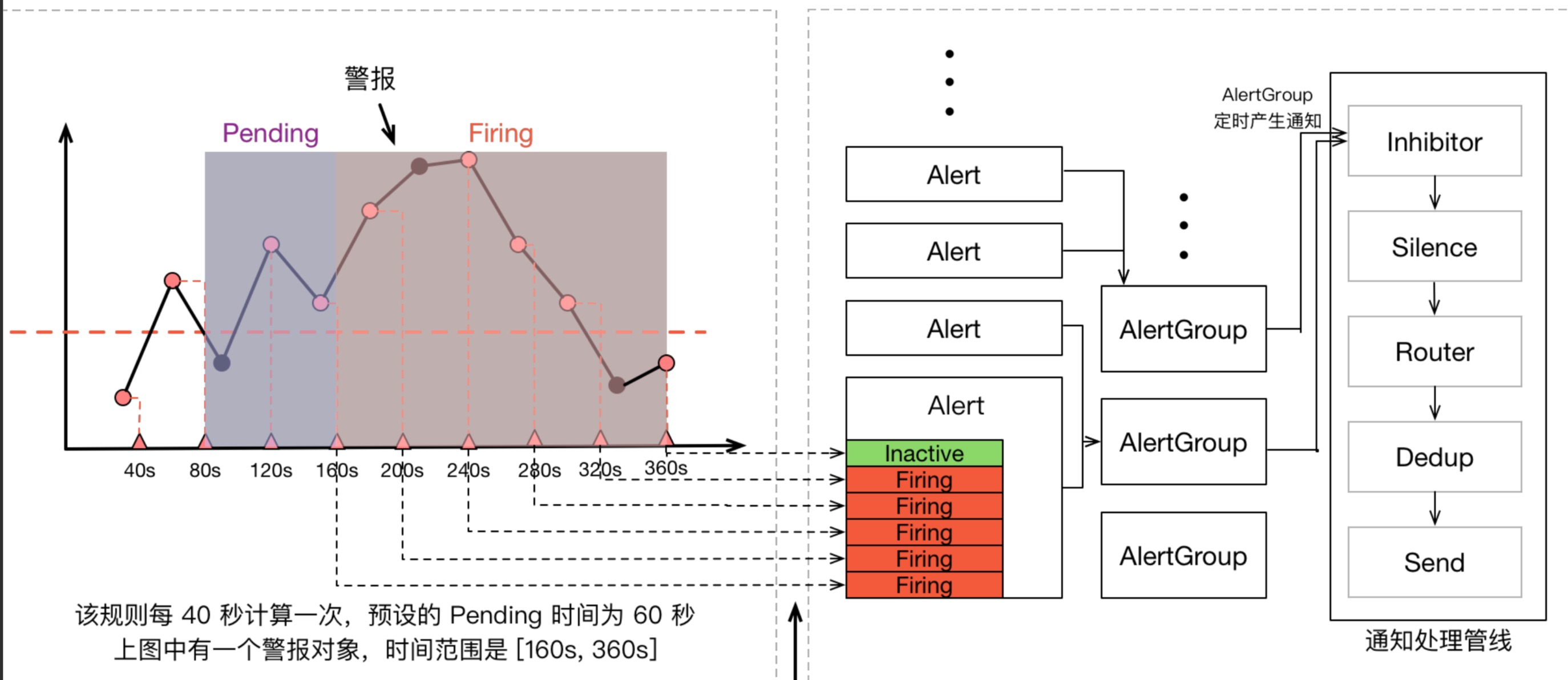
https://github.com/liyongxin/prometheus-webhook-wechat
自定义指标实现业务伸缩
Kubernetes Metrics API体系回顾
前面章节,我们讲过基于CPU和内存的HPA,即利用metrics-server及HPA,可以实现业务服务可以根据pod的cpu和内存进行弹性伸缩。
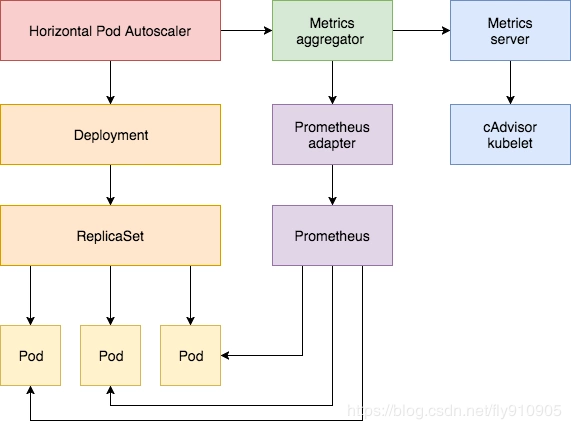
k8s对监控接口进行了标准化:
-
Resource Metrics
对应的接口是 metrics.k8s.io,主要的实现就是 metrics-server
-
Custom Metrics
对应的接口是 custom.metrics.k8s.io,主要的实现是 Prometheus, 它提供的是资源监控和自定义监控
安装完metrics-server后,利用kube-aggregator的功能,实现了metrics api的注册。可以通过如下命令
$ kubectl api-versions
...
metrics.k8s.io/v1beta1
HPA通过使用该API获取监控的CPU和内存资源:
# 查询nodes节点的cpu和内存数据
$ kubectl get --raw="/apis/metrics.k8s.io/v1beta1/nodes"|jq
$ kubectl get --raw="/apis/metrics.k8s.io/v1beta1/pods"|jq
# 若本机没有安装jq命令,可以参考如下方式进行安装
$ wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
$ rpm -ivh epel-release-latest-7.noarch.rpm
$ yum install -y jq
同样,为了实现通用指标的采集,需要部署Prometheus Adapter,来提供custom.metrics.k8s.io,作为HPA获取通用指标的入口。
Adapter安装对接
项目地址为: https://github.com/DirectXMan12/k8s-prometheus-adapter
$ git clone https://github.com/DirectXMan12/k8s-prometheus-adapter.git
# 最新release版本v0.7.0,代码切换到v0.7.0分支
$ git checkout v0.7.0
查看部署说明 https://github.com/DirectXMan12/k8s-prometheus-adapter/tree/v0.7.0/deploy
-
镜像使用官方提供的v0.7.0最新版 https://hub.docker.com/r/directxman12/k8s-prometheus-adapter/tags
-
准备证书
$ export PURPOSE=serving $ openssl req -x509 -sha256 -new -nodes -days 365 -newkey rsa:2048 -keyout ${PURPOSE}.key -out ${PURPOSE}.crt -subj "/CN=ca" $ kubectl -n monitor create secret generic cm-adapter-serving-certs --from-file=./serving.crt --from-file=./serving.key # 查看证书 $ kubectl -n monitor describe secret cm-adapter-serving-certs -
准备资源清单
$ mkdir yamls $ cp manifests/custom-metrics-apiserver-deployment.yaml yamls/ $ cp manifests/custom-metrics-apiserver-service.yaml yamls/ $ cp manifests/custom-metrics-apiservice.yaml yamls/ $ cd yamls # 新建rbac文件 $ vi custom-metrics-apiserver-rbac.yaml kind: ServiceAccount apiVersion: v1 metadata: name: custom-metrics-apiserver namespace: monitor --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-metrics-resource-cluster-admin roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: custom-metrics-apiserver namespace: monitor # 新建配置文件 $ vi custom-metrics-configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: adapter-config namespace: monitor data: config.yaml: | rules: - {} -
替换命名空间
# 资源清单文件默认用的命名空间是custom-metrics,替换为本例中使用的monitor $ sed -i 's/namespace: custom-metrics/namespace: monitor/g' yamls/* -
配置adapter对接的Prometheus地址
# 由于adapter会和Prometheus交互,因此需要配置对接的Prometheus地址 # 替换掉28行:yamls/custom-metrics-apiserver-deployment.yaml 中的--prometheus-url $ vim yamls/custom-metrics-apiserver-deployment.yaml ... 18 spec: 19 serviceAccountName: custom-metrics-apiserver 20 containers: 21 - name: custom-metrics-apiserver 22 image: directxman12/k8s-prometheus-adapter-amd64 23 args: 24 - --secure-port=6443 25 - --tls-cert-file=/var/run/serving-cert/serving.crt 26 - --tls-private-key-file=/var/run/serving-cert/serving.key 27 - --logtostderr=true 28 - --prometheus-url=http://prometheus:9090/ 29 - --metrics-relist-interval=1m 30 - --v=10 31 - --config=/etc/adapter/config.yaml ... -
部署服务
$ kubectl create -f yamls/
验证一下:
$ kubectl api-versions
custom.metrics.k8s.io/v1beta1
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 |jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": []
}
通用指标示例程序部署
为了演示效果,我们新建一个deployment来模拟业务应用。
$ cat custom-metrics-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: custom-metrics-demo
spec:
selector:
matchLabels:
app: custom-metrics-demo
template:
metadata:
labels:
app: custom-metrics-demo
spec:
containers:
- name: custom-metrics-demo
image: cnych/nginx-vts:v1.0
resources:
limits:
cpu: 50m
requests:
cpu: 50m
ports:
- containerPort: 80
name: http
部署:
$ kubectl create -f custom-metrics-demo.yaml
$ kubectl get po -o wide
custom-metrics-demo-95b5bc949-xpppl 1/1 Running 0 65s 10.244.1.194
$ curl 10.244.1.194/status/format/prometheus
...
nginx_vts_server_requests_total{host="*",code="1xx"} 0
nginx_vts_server_requests_total{host="*",code="2xx"} 8
nginx_vts_server_requests_total{host="*",code="3xx"} 0
nginx_vts_server_requests_total{host="*",code="4xx"} 0
nginx_vts_server_requests_total{host="*",code="5xx"} 0
nginx_vts_server_requests_total{host="*",code="total"} 8
...
注册为Prometheus的target:
$ cat custom-metrics-demo-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: custom-metrics-demo
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/status/format/prometheus"
spec:
ports:
- port: 80
targetPort: 80
name: http
selector:
app: custom-metrics-demo
type: ClusterIP
自动注册为Prometheus的采集Targets。
通常web类的应用,会把每秒钟的请求数作为业务伸缩的指标依据。
实践:
使用案例应用custom-metrics-demo,如果custom-metrics-demo最近2分钟内每秒钟的请求数超过10次,则自动扩充业务应用的副本数。
-
配置自定义指标
告诉Adapter去采集转换哪些指标,Adapter支持转换的指标,才可以作为HPA的依据
-
配置HPA规则
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: nginx-custom-hpa namespace: default spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: custom-metrics-demo minReplicas: 1 maxReplicas: 3 metrics: - type: Pods pods: metricName: nginx_vts_server_requests_per_second targetAverageValue: 10
Adapter配置自定义指标
思考:
前面讲CPU的平均使用率的采集,其实是通过node_cpu_seconds_total指标计算得到的。
^
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="idle"}
│ . . . . . . . . . . . . . . . . . . . node_cpu{cpu="cpu0",mode="system"}
│ . . . . . . . . . . . . . . . . . . node_load1{}
│ . . . . . . . . . . . . . . . . . . node_cpu_seconds_total{...}
v
<------------------ 时间 ---------------->
同样,如果想获得每个业务应用最近2分钟内每秒的访问次数,也是根据总数来做计算,因此,需要使用业务自定义指标nginx_vts_server_requests_total,配合rate方法即可获取每秒钟的请求数。
rate(nginx_vts_server_requests_total[2m])
# 如查询有多条数据,需做汇聚,需要使用sum
sum(rate(nginx_vts_server_requests_total[2m])) by(kubernetes_pod_name)
-
自定义指标可以配置多个,因此,需要将规则使用数组来配置
rules: - {} -
告诉Adapter,哪些自定义指标可以使用
rules: - seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}'seriesQuery是PromQL语句,和直接用
nginx_vts_server_requests_total查询到的结果一样,凡是seriesQuery可以查询到的指标,都可以用作自定义指标 -
告诉Adapter,指标中的标签和k8s中的资源对象的关联关系
rules: - seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"}我们查询到的可用指标格式为:
nginx_vts_server_requests_total{code="1xx",host="*",instance="10.244.1.194:80",job="kubernetes-sd-endpoints",kubernetes_name="custom-metrics-demo",kubernetes_namespace="default",kubernetes_pod_name="custom-metrics-demo-95b5bc949-xpppl"}由于HPA在调用Adapter接口的时候,告诉Adapter的是查询哪个命名空间下的哪个Pod的指标,因此,Adapter在去查询的时候,需要做一层适配转换(因为并不是每个prometheus查询到的结果中都是叫做
kubernetes_namespace和kubernetes_pod_name) -
指定自定义的指标名称,供HPA配置使用
rules: - seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pods"} name: matches: "^(.*)_total" as: "${1}_per_second"因为Adapter转换完之后的指标含义为:每秒钟的请求数。因此提供指标名称,该配置根据正则表达式做了匹配替换,转换完后的指标名称为:
nginx_vts_server_requests_per_second,HPA规则中可以直接配置该名称。 -
告诉Adapter如何获取最终的自定义指标值
rules: - seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}' resources: overrides: kubernetes_namespace: {resource: "namespace"} kubernetes_pod_name: {resource: "pod"} name: matches: "^(.*)_total" as: "${1}_per_second" metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'我们最终期望的写法可能是这样:
sum(rate(nginx_vts_server_requests_total{host="*",code="total",kubernetes_namespace="default"}[2m])) by (kubernetes_pod_name)但是Adapter提供了更简单的写法:
sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)Series: 指标名称LabelMatchers: 指标查询的labelGroupBy: 结果分组,针对HPA过来的查询,都会匹配成kubernetes_pod_name
更新Adapter的配置:
$ vi custom-metrics-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitor
data:
config.yaml: |
rules:
- seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>))
需要更新configmap并重启adapter服务:
$ kubectl apply -f custom-metrics-configmap.yaml
$ kubectl -n monitor delete po custom-metrics-apiserver-c689ff947-zp8gq
再次查看可用的指标数据:
$ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 |jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "namespaces/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "pods/nginx_vts_server_requests_per_second",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
我们发现有两个可用的resources,引用官方的一段解释:
Notice that we get an entry for both "pods" and "namespaces" -- the adapter exposes the metric on each resource that we've associated the metric with (and all namespaced resources must be associated with a namespace), and will fill in the <<.GroupBy>> section with the appropriate label depending on which we ask for.
We can now connect to $KUBERNETES/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_vts_server_requests_per_second, and we should see
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_vts_server_requests_per_second" | jq
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/nginx_vts_server_requests_per_second"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "custom-metrics-demo-95b5bc949-xpppl",
"apiVersion": "/v1"
},
"metricName": "nginx_vts_server_requests_per_second",
"timestamp": "2020-08-02T04:07:06Z",
"value": "133m",
"selector": null
}
]
}
其中133m等于0.133,即当前指标查询每秒钟请求数为0.133次
https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/config-walkthrough.md
https://github.com/DirectXMan12/k8s-prometheus-adapter/blob/master/docs/config.md
配置HPA实现自定义指标的业务伸缩
$ cat hpa-custom-metrics.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: nginx-custom-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: custom-metrics-demo
minReplicas: 1
maxReplicas: 3
metrics:
- type: Pods
pods:
metricName: nginx_vts_server_requests_per_second
targetAverageValue: 10
$ kubectl create -f hpa-custom-metrics.yaml
$ kubectl get hpa
注意metricName为自定义的指标名称。
使用ab命令压测custom-metrics-demo服务,观察hpa的变化:
$ kubectl get svc -o wide
custom-metrics-demo ClusterIP 10.104.110.245 <none> 80/TCP 16h
$ ab -n1000 -c 5 http://10.104.110.245:80/
观察hpa变化:
$ kubectl describe hpa nginx-custom-hpa
查看adapter日志:
$ kubectl -n monitor logs --tail=100 -f custom-metrics-apiserver-c689ff947-m5vlr
...
I0802 04:43:58.404559 1 httplog.go:90] GET /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/nginx_vts_server_requests_per_second?labelSelector=app%3Dcustom-metrics-demo: (20.713209ms) 200 [kube-controller-manager/v1.16.0 (linux/amd64) kubernetes/2bd9643/system:serviceaccount:kube-system:horizontal-pod-autoscaler 172.21.51.67:60626]
实际的请求:
http://prometheus:9090/api/v1/query?query=%28sum%28rate%28nginx_vts_server_requests_per_second%7Bkubernetes_namespace%3D%22default%22%2Ckubernetes_pod_name%3D~%22custom-metrics-demo-95b5bc949-9vd8q%7Ccustom-metrics-demo-95b5bc949-qrpnp%22%2Cjob%3D%22kubernetes-sd-endpoints%22%7D%5B1m%5D%29%29+by+%28kubernetes_pod_name
I1028 08:56:05.289421 1 api.go:74] GET http://prometheus:9090/api/v1/query?query=%28sum%28rate%28nginx_vts_server_requests_total%7Bkubernetes_namespace%3D%22default%22%2Ckubernetes_pod_name%3D~%22custom-metrics-demo-95b5bc949-9vd8q%7Ccustom-metrics-demo-95b5bc949-qrpnp%22%7D%5B1m%5D%29%29+by+%28kubernetes_pod_name%29%29&time=1603875365.284 200 OK
补充:coredns通用指标的hpa
添加指标:
$ cat custom-metrics-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitor
data:
config.yaml: |
rules:
- seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
as: "nginx_vts_server_requests_per_second"
metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>))
- seriesQuery: 'coredns_dns_request_count_total{job="kubernetes-sd-endpoints"}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
as: "coredns_dns_request_count_total_1minute"
metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>,job="kubernetes-sd-endpoints"}[1m])) by (<<.GroupBy>>))
coredns的hpa文件:
$ cat coredns-hpa.yaml
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: coredns-hpa
namespace: kube-system
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: coredns
minReplicas: 2
maxReplicas: 3
metrics:
- type: Pods
pods:
metricName: coredns_dns_request_count_total_1minute
targetAverageValue: 1
hpa会拿pod、namespace去通过adaptor提供的api查询指标数据:
sum(rate(coredns_dns_request_count_total{kubernetes_namespace="default",kubernetes_pod_name=~"custom-metrics-demo-95b5bc949-9vd8q|custom-metrics-demo-95b5bc949-qrpnp",job="kubernetes-sd-endpoints"}[1m])) by (kubernetes_pod_name)
追加:Adapter查询数据和直接查询Prometheus数据不一致(相差4倍)的问题。
$ vi custom-metrics-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitor
data:
config.yaml: |
rules:
- seriesQuery: 'nginx_vts_server_requests_total{host="*",code="total"}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>,host="*",code="total"}[1m])) by (<<.GroupBy>>))
查询验证:
$ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/nginx_vts_server_requests_per_second" | jq
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/nginx_vts_server_requests_per_second"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "custom-metrics-demo-95b5bc949-xpppl",
"apiVersion": "/v1"
},
"metricName": "nginx_vts_server_requests_per_second",
"timestamp": "2020-08-02T04:07:06Z",
"value": "133m",
"selector": null
}
]
}